Bienvenido al curso Xano: ¡El poder del backend sin código! En este curso tendrás la oportunidad de aprender a dar tus primeros pasos en las mayores backend en el Código de hoy, Xano. Con Xano podrás escalar tus proyectos con miles de usuarios y disfrutar de los beneficios de las herramientas en Código, ofreciendo agilidad y flexibilidad.
Este curso práctico ofrece la oportunidad de aprender del instructor Louis, especialista en la herramienta Xano Backend y uno de los nombres más importantes del área en Brasil. Además, Louis forma parte del equipo de Xano en Estados Unidos, lo que le convierte en uno de los mayores referentes del mercado en relación a Xano.
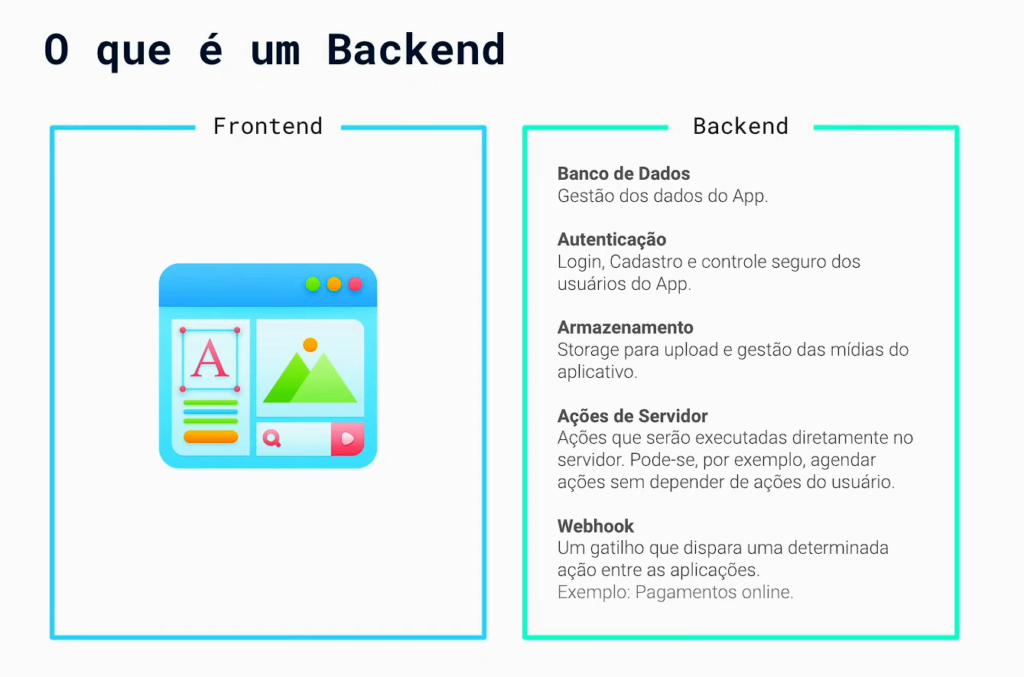
Antes de iniciar el curso, es importante repasar algunos conceptos fundamentales. Un software siempre consta de un front-end y un back-end. oh backend es responsable de todos los aspectos de la base de datos, gestión de datos, autenticación, seguridad del usuario, almacenamiento de medios, acciones del servidor y webhooks.
Contenido
Conceptos importantes
Los conceptos fundamentales que son esenciales para comprender completamente cómo funciona Xano incluyen API, acciones CRUD y uso de bases de datos.
API
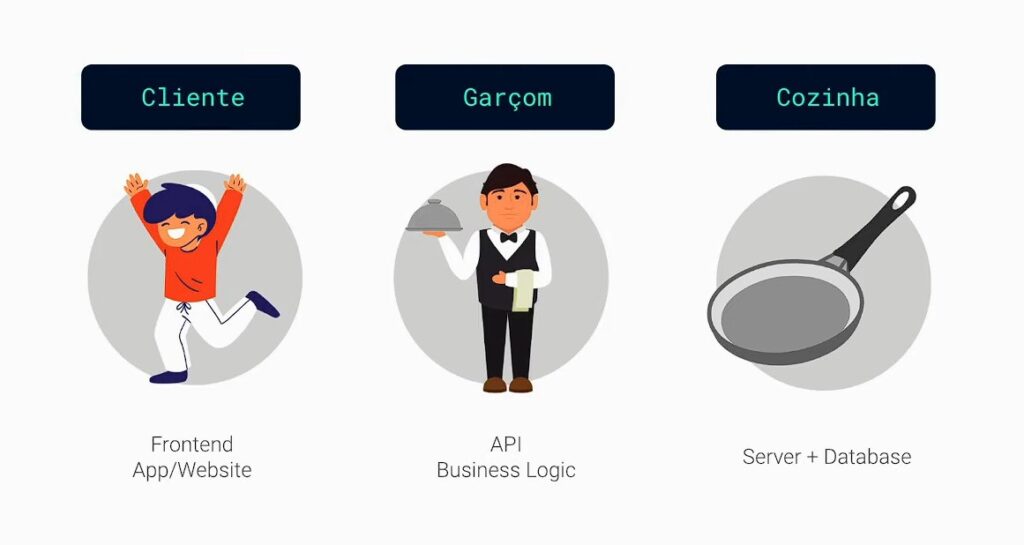
En primer lugar, tenemos las API, que se utilizan para la comunicación entre sistemas. En el contexto de Xano, son vitales para conectar el front-end y el back-end, permitiendo el intercambio de datos necesarios para que la aplicación funcione.
Acciones CRUD
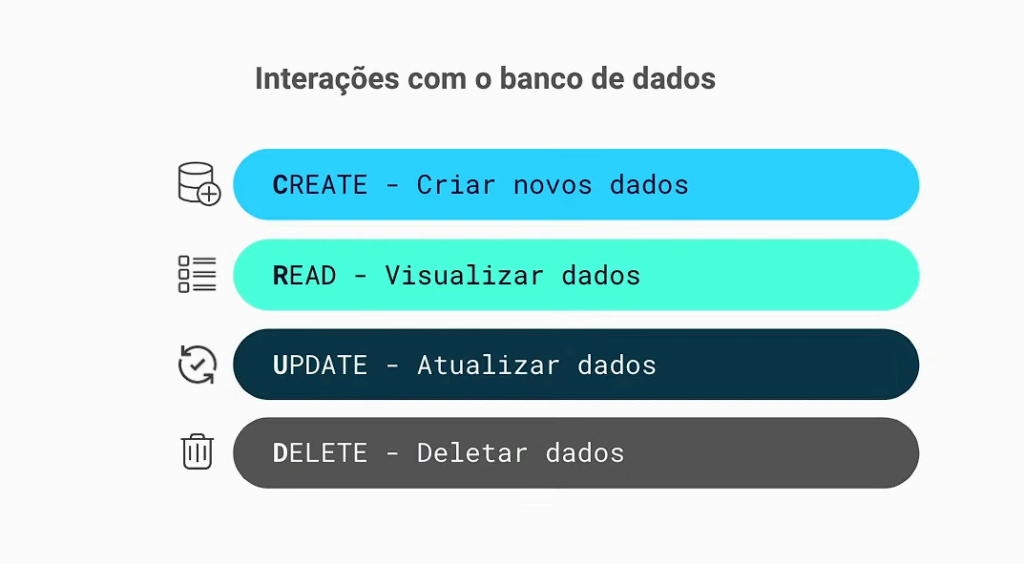
Continuando tenemos las acciones CRUD (Crear, Leer, Actualizar, Eliminar) que son fundamentales para interactuar con la base de datos. Permiten la creación, lectura, actualización y eliminación de datos, proporcionando las funcionalidades necesarias para manipular la información almacenada.
El poder de Xano
Xano es un potente backend no-code que ofrece agilidad y flexibilidad en la creación de aplicaciones. Las ventajas de Xano incluyen el uso de la base de datos Postgres, que es altamente escalable y segura. Además, Xano ofrece la posibilidad de crear API fácilmente, permitiendo la creación de nuevas funciones e interacciones con la base de datos de forma rápida y flexible.
Además, Xano también es compatible con las certificaciones de cumplimiento y protección de datos más importantes, como SOC2, GDPR, IPA e ISO 27001.
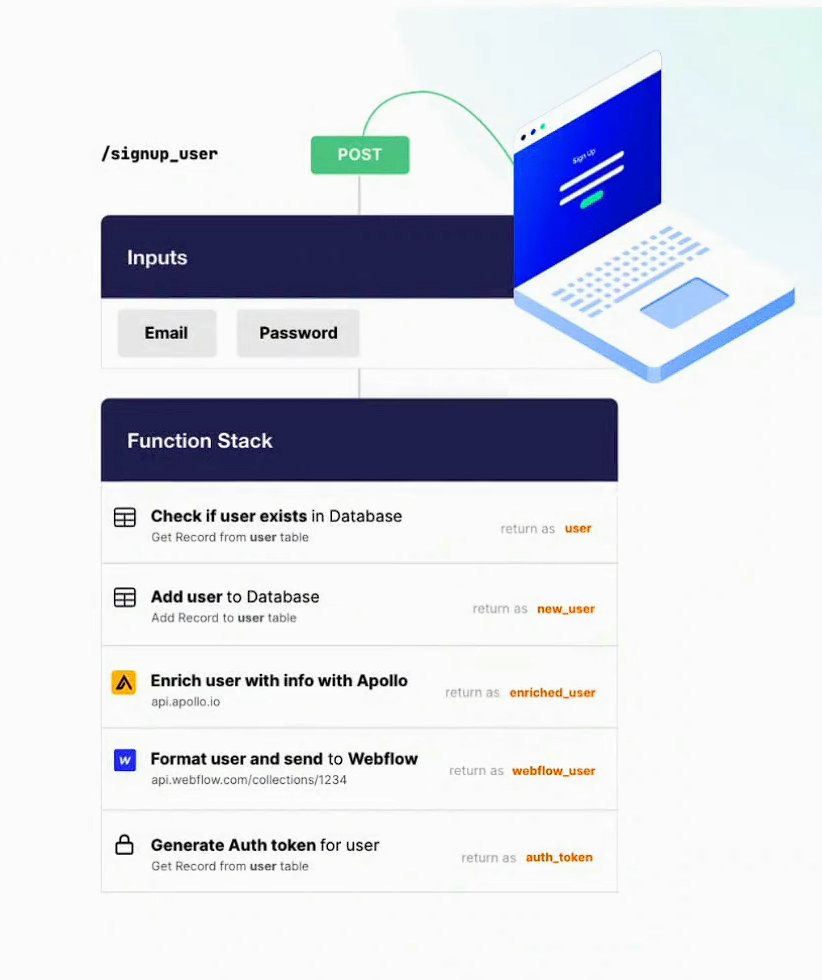
Finalmente, Xano permite la creación de API de forma sencilla, con la capacidad de crear, leer, editar y eliminar datos de la base de datos, todo a través de API, facilitando la integración con otras herramientas no-code. De esta forma, Xano se destaca como una herramienta práctica, flexible y segura para conectar el front-end con el back-end.
Comenzando el curso Xano
Ahora que te has dado cuenta de que Xano es una herramienta increíble, pasemos a la parte práctica, y por eso te invito a ver el vídeo a continuación que contiene el curso completo de Xano.
Ahora que conoce los conceptos básicos sobre una de las mejores herramientas backend nocode del mercado, ¡comparta su opinión en los comentarios! Y si tienes alguna duda, déjanos un comentario y estaremos encantados de responderte.
Y así, para aquellos que quieran aprender a utilizar Xano profesionalmente junto con otras herramientas front-end y poder crear una aplicación desde cero, tenemos varios cursos y rutas de aprendizaje.
Neto se especializó en Bubble debido a la necesidad de crear tecnologías de forma rápida y económica para su startup, y desde entonces ha estado creando sistemas y automatizaciones con IA. En la Cumbre de Desarrolladores de Bubble 2023, fue reconocido como uno de los mentores de Bubble más destacados del mundo. En diciembre, fue nombrado miembro destacado de la comunidad global NoCode en los Premios NoCode 2023 y ganó el primer lugar en la competencia a la mejor aplicación organizada por la propia Bubble. Actualmente, Neto se centra en la creación de soluciones y automatizaciones de agentes de IA utilizando N8N y OpenAI.
Hablando claro: 2026 será un año de cambio para quienes quieran ganar dinero con... IA (Inteligencia Artificial). Existen oportunidades, pero no todas merecen la pena y algunas prometen mucho más de lo que ofrecen.
En este artículo, he organizado las principales formas de monetizar la IA en categorías claras, con ventajas, desventajas y el nivel real de esfuerzo involucrado. La idea aquí es ayudarte a elegir un camino consciente, sin caer en atajos ilusorios.
Contenido
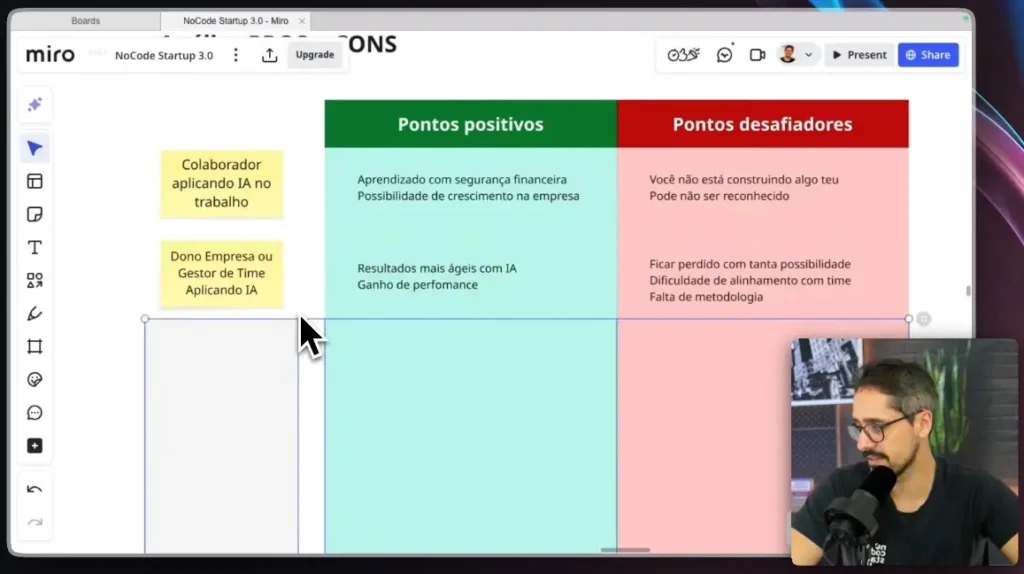
IA aplicada al ámbito laboral como empleado (carrera y seguridad)
Si ya trabajas para una empresa, aplicar IA a tu rutina diaria es una de las formas más seguras de empezar. Aprendes, experimentas y construyes proyectos reales sin sacrificar la estabilidad financiera.
Es posible crear automatizaciones internas, agentes e incluso softwares que aumenten la eficiencia, reduzcan costos y generen un impacto directo en el negocio. Cuando eso sucede, el reconocimiento tiende a llegar, siempre y cuando se generen resultados reales y no solo se "use la IA por el simple hecho de usarla".
El punto clave a entender es que no estás construyendo algo que sea tuyo. Aun así, para el aprendizaje y el crecimiento profesional, este es uno de los mejores puntos de entrada.
IA para gerentes y propietarios de empresas
Para los gerentes y propietarios de empresas, la IA quizás represente la La mayor oportunidad financiera de 2026. La mayoría de las empresas todavía están perdidas, carentes de método, estrategia y claridad sobre cómo aplicar la IA a sus procesos.
Cuando se aplica correctamente, la IA mejora el rendimiento, reduce los cuellos de botella y acelera los resultados en ventas, servicio al cliente y operaciones. El desafío radica en el exceso de herramientas y la falta de una metodología clara para el equipo.
Quien logre organizar este caos y aplicar la IA con foco en resultados capturará mucho valor. Realmente hay mucho dinero en juego aquí.
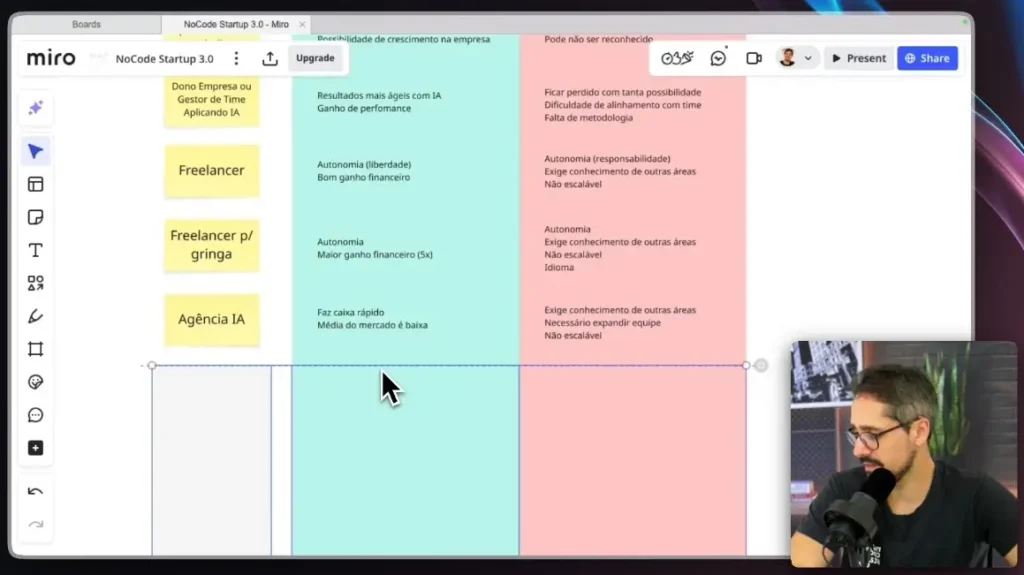
Prestación de servicios impulsada por IA: una descripción general
La Prestación de servicios impulsada por IA Es una de las formas más rápidas de generar ingresos. Resuelve problemas empresariales reales utilizando automatización, agentes y sistemas inteligentes.
Este modelo se desarrolla en freelance, freelance para clientes internacionales, agencia y consultoría. Cada uno tiene un nivel diferente de esfuerzo, retorno y complejidad, pero todos requieren ejecución.
Aquí es donde muchas personas realmente empiezan a "hacer girar las ruedas".
Trabajador independiente trabajando en el extranjero (ganancias en dólares)
Trabajar como freelance para empresas internacionales es, sin exagerar, una de las mejores opciones para ganar dinero con IA. Ganar en dólares o euros cambia completamente el juego.
Todavía estás intercambiando tiempo por dinero, pero con un rendimiento mucho mayor. El mayor reto es el comienzo: conseguir el primer proyecto y manejar el lenguaje, incluso a un nivel básico.
Después de que llega el primer cliente, empiezan a llegar las referencias. Para aquellos que desean resultados rápidos y están dispuestos a vender su propio servicio, este camino es extremadamente atractivo.
Creando una agencia de IA
Las agencias de IA son la evolución natural del trabajo freelance. Aquí escalas personas, proyectos e ingresos.
El mercado aún es inmaduro, mucha gente hace todo mal y esto crea oportunidades para quienes hacen bien lo básico. Puede cerrar acuerdos, formar equipos y ofrecer soluciones completas con IA.
El desafío entonces es la gestión: personas, plazos, procesos y calidad. Aun así, para 2026, será una de las formas más rápidas de monetizar consistentemente la IA.
👉 Únete a la Formación en codificación de IA Aprenda a crear indicaciones completas, automatizaciones y aplicaciones impulsadas por IA, pasando de cero a proyectos del mundo real en tan solo unos días.
Consultoría de IA para empresas
La consultoría es un modelo extremadamente lucrativo, pero No es un punto de partida.. Requiere experiencia práctica, comprensión del proceso y habilidades de diagnóstico.
El retorno financiero suele ser alto en relación al tiempo invertido. Por otro lado, es necesario tener autoridad, trayectoria y un portafolio real de proyectos.
Para aquellos que tienen experiencia en agencias, desarrollo de productos o implementaciones a gran escala, esta es una excelente trayectoria profesional. Para los principiantes, todavía no tiene sentido.
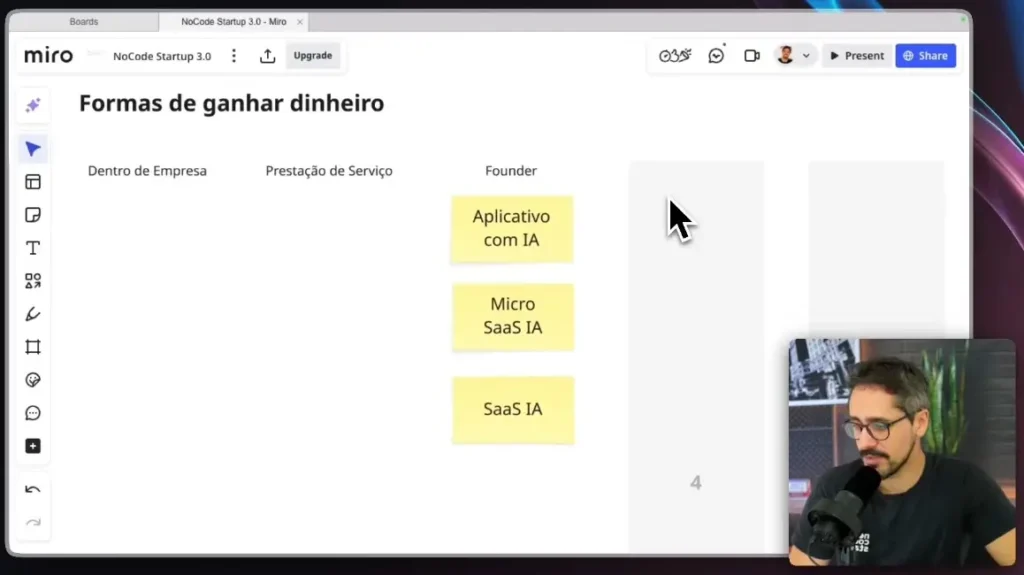
Fundador: Creación de aplicaciones impulsadas por IA
Crear aplicaciones impulsadas por IA nunca ha sido más accesible. Herramientas como Amable, Cursor e integraciones con Supabase Lo hacen posible incluso sin conocimientos técnicos.
El potencial financiero es alto, pero también lo es la dificultad. La creación de tecnología ya no es el factor diferenciador: hoy, el desafío está en el marketing, la distribución, las finanzas y la validación.
Es un camino de mucho aprendizaje, pero con un alto índice de error al inicio. Vale la pena si estás dispuesto a cometer errores, aprender e iterar.
Micro SaaS con IA (pros y contras)
O Micro SaaS Resuelve un problema específico para un nicho específico. Esto reduce la competencia y aumenta la claridad de la oferta.
No escala como un SaaS tradicional, pero puede generar ingresos consistentes y sostenibles. El desafío sigue siendo el mismo: marketing, ventas y gestión.
No es fácil ni rápido, pero puede ser un gran negocio secundario. Aquí lo clasifico como un camino “aceptable”, siempre y cuando tengas paciencia.
SaaS tradicional con IA
O SaaS tradicional Tiene mayor potencial de escalamiento, pero también mayor competencia. Resuelve problemas más amplios y compite en mercados más grandes.
Esto requiere más tiempo, más capital emocional y mayor capacidad de ejecución. Por lo tanto, el Micro SaaS a menudo termina siendo una opción más inteligente al principio.
SaaS es poderoso, pero definitivamente no es el camino más fácil.
Educación impulsada por IA: cursos y productos digitales
La educación impulsada por IA es extremadamente escalable. Una vez que el producto está listo, la entrega es casi automática.
El problema es el tiempo. Crear una audiencia, producir contenido y establecer autoridad lleva meses, a veces años.
Aquí en Inicio sin código, Nos llevó bastante tiempo hasta que el proyecto se volviera verdaderamente relevante desde el punto de vista financiero. Funciona, pero requiere constancia y visión a largo plazo.
Comunidades de IA
Las comunidades generan redes, negocios repetidos y autoridad. Pero también requieren presencia constante, eventos, apoyo y mucha energía.
Es un modelo potente, pero laborioso. No lo recomiendo como primer paso para aquellos que recién empiezan.
Con experiencia y audiencia, puede convertirse en un activo increíble.
Plantillas, libros electrónicos y productos sencillos impulsados por IA.
Las plantillas y los libros electrónicos son fáciles de crear y escalar. Es precisamente por eso que la competencia es feroz y el valor percibido tiende a ser bajo.
Hoy en día, si algo se puede resolver con una pregunta en ChatGPT, Es difícil vender sólo información. Estos productos funcionan mejor como complemento, no como negocio principal.
Para ganar dinero real con IA, entregue ejecución y resultado Esto es lo que hace la diferencia.
Siguiente paso
No existe dinero fácil con IA. Lo que existe es Más acceso, más herramientas y más posibilidades. Para los que se desempeñan bien.
Los caminos más sólidos pasan por ofrecer servicios, productos bien posicionados y construir autoridad. Cuanto más fácil parece algo, mayor tiende a ser la competencia.
Si quieres aprender IA de forma práctica y estructurada, centrada en proyectos del mundo real, echa un vistazo... Formación en codificación de IA.
La tecnología está experimentando una transición histórica: de los software pasivos a los sistemas autónomos. Comprender la tipos de agentes de IA Se trata de descubrir herramientas capaces de percibir, razonar y actuar de forma independiente para alcanzar objetivos complejos, sin necesidad de microgestión.
Esta evolución ha transformado el mercado. Para los profesionales que quieren liderar el... Infraestructura de IA, Dominar la taxonomía de estos agentes ya no es opcional.
Es el diferenciador competitivo exacto entre lanzar un chatbot básico u orquestar una fuerza de trabajo digital completa.
En esta guía definitiva, analizaremos la anatomía de los agentes y exploraremos todo, desde las clasificaciones clásicas hasta las arquitecturas modernas basadas en LLM que están revolucionando los mundos No-Code y High-Code.
Diagrama que ilustra el ciclo de percepción, razonamiento y acción de diferentes tipos de agentes de IA en un entorno digital.
¿Qué define exactamente a un agente de IA?
Antes de explorar los tipos, es crucial establecer una línea clara. Un agente de inteligencia artificial no es simplemente un modelo de lenguaje ni un algoritmo de aprendizaje automático.
La definición más rigurosa, aceptada tanto en el ámbito académico como en la industria, como en el curso Stanford CS221, describe a un agente como una entidad computacional situada en un entorno, capaz de percibirlo a través de sensores y actuar sobre él a través de actuadores para maximizar sus posibilidades de éxito.
La diferencia crucial: modelo de IA vs. agente de IA
Muchos principiantes confunden el motor con el coche.
Modelo de IA (por ejemplo, GPT-4, Llama 3): Es el cerebro pasivo. Si no le envías una señal, no hace nada. Tiene conocimiento, pero no capacidad de acción.
Agente de IA: Es el sistema completo. Tiene el modelo como herramienta central de razonamiento, pero también tiene memoria, acceso a herramientas (bases de datos, API, navegadores) y, fundamentalmente, un objetivo.
Un agente utiliza las predicciones del modelo para tomar decisiones secuenciales, gestionar estados y corregir el curso de sus acciones.
Es la diferencia entre preguntarle a ChatGPT "cómo enviar un correo electrónico" (Plantilla) y tener un software que escribe, programa y envía de forma autónoma el correo electrónico a su lista de contactos (Agente).
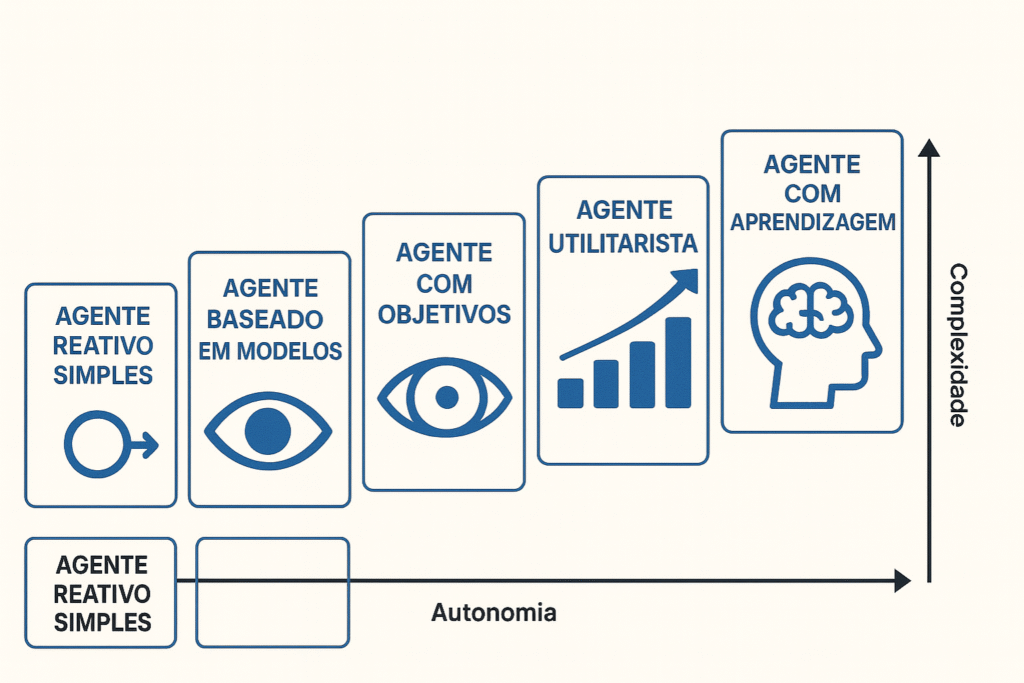
Los 5 tipos clásicos de agentes de IA
Para construir soluciones sólidas, necesitamos revisar la base teórica establecida por Stuart Russell y Peter Norvig, los padres de la IA moderna.
La complejidad de un agente está determinada por su capacidad para manejar incertidumbres y mantener estados internos.
Aquí están los 5 tipos de agentes de IA estructuras jerárquicas que forman la base de cualquier automatización inteligente:
1. Agentes reactivos simples
Este es el nivel más básico de inteligencia. Los agentes reactivos simples operan según el principio "si-entonces".
Sólo responden a la entrada actual, ignorando por completo el historial o los estados pasados.
Cómo funciona: Si el sensor detecta "X", el actuador hace "Y".
Ejemplo: Un termostato inteligente o un filtro antispam básico. Si la temperatura supera los 25 °C, enciende el aire acondicionado.
Limitación: Fracasan en entornos complejos donde la decisión depende de un contexto histórico.
2. Agentes reactivos basados en modelos
Yendo un paso más allá, estos agentes mantienen un estado interno: una especie de memoria a corto plazo.
No sólo miran el "ahora", sino que consideran cómo evoluciona el mundo independientemente de sus acciones.
Esto es vital para tareas donde el entorno no es completamente observable. Por ejemplo, en un coche autónomo, el agente debe recordar que hace dos segundos había un peatón en la acera, incluso si un camión le bloqueó la vista momentáneamente.
3. Agentes basados en objetivos
La verdadera inteligencia empieza aquí. Los agentes orientados a objetivos no solo reaccionan; planifican.
Tienen una descripción clara de un estado “deseable” (la meta) y evalúan diferentes secuencias de acciones para lograrlo.
Esto introduce capacidades de búsqueda y planificación. Si el objetivo es optimizar la base de datos, el agente puede simular varias rutas antes de ejecutar el comando final, algo esencial para quienes trabajan con... IA para el análisis de datos.
4. Agentes basados en utilidades
A menudo, alcanzar el objetivo no basta; es necesario lograrlo de la mejor manera posible. Los agentes basados en la utilidad utilizan una función de utilidad (puntuación) para medir la preferencia entre diferentes estados.
Si un agente logístico desea entregar un paquete, el agente de servicios públicos calculará no solo la ruta para llegar, sino también la ruta más rápida, con el menor consumo de combustible y la mayor seguridad. Se trata de maximizar la eficiencia.
5. Agentes con aprendizaje
En la cima de la jerarquía clásica se encuentran los agentes capaces de evolucionar. Tienen un componente de aprendizaje que analiza la retroalimentación de sus acciones pasadas para mejorar su desempeño futuro.
Comienzan con conocimientos básicos y, mediante la exploración del entorno, ajustan sus propias reglas de decisión. Este es el principio que sustenta los sistemas de recomendación avanzados y la robótica adaptativa.
Infografía que compara la complejidad y autonomía de cinco tipos clásicos de agentes de IA, desde los reactivos simples hasta los agentes de aprendizaje.
¿En qué se basan los agentes generativos en los LLM?
La taxonomía clásica ha evolucionado. Con la llegada de los Grandes Modelos del Lenguaje (LLM), ha surgido una nueva categoría que domina el debate actual: Agentes generativos.
En estos sistemas, el LLM actúa como el controlador central o "cerebro", utilizando su vasta base de conocimientos para razonar sobre problemas que no fueron programados explícitamente, como se detalla en el artículo fundamental sobre... Agentes generativos.
Marcos de razonamiento: ReAct y CoT
Para que un LLM funcione como un agente eficaz, utilizamos técnicas de ingeniería rápida principios avanzados que estructuran el pensamiento del modelo:
Cadena de pensamiento (CdP): Se le indica al agente que descomponga problemas complejos en pasos intermedios de razonamiento lógico ("Pensemos paso a paso"). Las investigaciones indican que esta técnica... Estimula el razonamiento complejo. en modelos grandes.
ReAct (Razonar + Actuar): Esta es la arquitectura más popular actualmente. El agente genera un pensamiento (Razón), ejecuta una acción en una herramienta externa (Acción) y observa el resultado (Observación). Este bucle, descrito en el artículo... ReAct: Sinergizando razonamiento y acción, Esto le permite interactuar con API, leer documentación o ejecutar código Python en tiempo real.
Herramientas como AutoGPT y Bebé AGI Popularizaron el concepto de agentes autónomos que crean sus propias listas de tareas basándose en estos marcos.
Consejo en Especialista: Para aquellos que deseen profundizar en el diseño técnico de estos sistemas, nuestro Formación en codificación de IA Explora exactamente cómo orquestar estos marcos para crear software inteligentes.
Arquitecturas: Sistemas de agente único vs. sistemas multiagente
Al desarrollar una solución para su empresa, se enfrentará a una elección arquitectónica crítica: ¿debería utilizar un superagente que haga todo o varios especialistas?
¿Cuál es la diferencia entre sistemas de agente único y sistemas multiagente?
La diferencia radica en forma de organización de la inteligencia. Uno Agente único Concentra toda la lógica y ejecución en una sola entidad, haciéndolo más simple, rápido y fácil de mantener, ideal para tareas sencillas con un alcance bien definido.
Ya el Sistemas multiagente Distribuyen el trabajo entre agentes especializados, cada uno responsable de una función específica.
Este enfoque aumenta la capacidad de resolver problemas complejos, mejora la calidad de los resultados y facilita la escalabilidad de la solución.
¿Cuándo conviene utilizar un agente único?
Un solo agente es ideal para tareas lineales y de alcance limitado. Si el objetivo es "resumir este PDF y enviarlo por correo electrónico", un solo agente con las herramientas adecuadas es eficiente y fácil de mantener.
La latencia es menor y la complejidad del desarrollo se reduce.
El poder de la orquestación multiagente
Para problemas complejos, la industria está migrando a Sistemas multiagente (MAS). Imagina una agencia digital: no quieres que el redactor haga el diseño y apruebe el presupuesto.
Un agente "Investigador" que busca datos en la web.
Un agente "Analista" que procesa los datos.
Un agente llamado "Escritor" que crea el informe final.
Un agente “crítico” que revisa el trabajo antes de la entrega.
Esta especialización imita las estructuras organizativas humanas y tiende a producir resultados de mayor calidad.
Los marcos modernos facilitan esta orquestación, como LangGraph Para un control de flujo complejo, el CrewAI para equipos de agentes basados en roles, e incluso bibliotecas más ligeras como Agentes smolagents para abrazar la cara.
Representación visual de un sistema multiagente donde agentes especializados colaboran para resolver un problema empresarial complejo.
Aplicaciones prácticas y herramientas sin código
La teoría es fascinante, pero ¿cómo se traduce esto en valor real? Diferentes tipos de agentes de IA ya operan entre bastidores en operaciones startups grandes y ágiles.
Agentes de codificación y desarrollo
Agentes autónomos como Devin o implementaciones de código abierto como OpenDevin Utilizan arquitecturas y herramientas de planificación para escribir, depurar e implementar bases de código completas.
En el entorno No-Code, herramientas como FlutterFlow y Bubble Son agentes integradores que ayudan a construir interfaces y lógica complejas utilizando únicamente comandos de texto.
Agentes de análisis de datos
En lugar de depender de analistas para generar informes SQL manuales, los agentes orientados a objetivos y utilidades pueden conectarse a su almacén de datos, formular consultas, analizar tendencias y generar información proactiva.
Agentes de servicio al cliente (Experiencia del clienteLos agentes que no sólo responden preguntas sino que también acceden al CRM para procesar reembolsos o cambiar planes son ejemplos de agentes orientados a objetivos que generan un ROI inmediato.
Empresas como Zapier y el Fuerza de ventas Ya ofrecen plataformas dedicadas para crear estos asistentes corporativos.
Interfaz de un panel de negocios que muestra métricas de rendimiento optimizadas por agentes de IA autónomos.
Preguntas frecuentes sobre los agentes de IA
Estas son las preguntas más comunes que recibimos de la comunidad, que dominan las búsquedas en Google y en foros como... Reddit:
¿Cuál es la diferencia entre un chatbot y un agente de IA?
Un chatbot tradicional normalmente sigue un guión rígido o simplemente responde basándose en un texto entrenado.
Un agente de IA tiene autonomía: puede usar herramientas (como una calculadora, un calendario, un correo electrónico) para realizar tareas del mundo real, no solo conversar.
¿Qué son los agentes autónomos?
Estos sistemas pueden funcionar sin intervención humana constante. Se define un objetivo general (p. ej., "Descubrir las 5 mejores herramientas de SEO y crear una tabla comparativa") y el agente autónomo decide qué sitios web visitar, qué datos extraer y cómo formatear los resultados.
¿Necesito saber programar para crear un agente de IA?
No necesariamente. Si bien el conocimiento de la lógica es vital, las plataformas modernas y los frameworks sin código permiten la creación de agentes potentes mediante interfaces visuales y lenguaje natural.
Sin embargo, para personalizaciones avanzadas, es necesario comprender la lógica de Programación de IA Esta es una gran ventaja.
Concepto futurista de colaboración entre humanos e IA, donde los desarrolladores orquestan múltiples tipos de agentes de IA en un entorno de trabajo digital.
El futuro es agente y requiere arquitectos, no solo usuarios
Entendiendo el tipos de agentes AI Es el primer paso para pasar de ser un consumidor de tecnología a ser un creador de soluciones.
Ya sea un simple agente reactivo para la clasificación de correo electrónico o un complejo sistema multiagente para gestionar operaciones de comercio electrónico, la autonomía digital es la nueva frontera de la productividad.
El mercado ya no busca sólo a quienes saben utilizar ChatGPT, sino a quienes saben... diseño de flujos de trabajo que ChatGPT (y otros modelos) ejecutarán.
Si quieres ir más allá de la teoría y dominar el desarrollo de estas herramientas, el siguiente paso ideal es aprender sobre nuestras... Capacitación para administradores de agentes de IA. La era de los agentes recién comienza, y tú podrías estar a cargo de ella.
Si buscas crear proyectos más avanzados, con mejor seguridad, mayor escalabilidad y más profesionalismo utilizando las herramientas de Codificación Vibe, Esta guía es para ti.
En este artículo he descrito tres consejos muy importantes que te guiarán desde el nivel principiante hasta proyectos avanzados y verdaderamente profesionales.
Necesitamos ir más allá de una simple interfaz visual y construir una arquitectura sólida. ¡Vamos!
Contenido
¿Por qué combinar Lovable, N8N y Supabase?
Consejo 1: Comience por centrarse en el problema principal
Mi primer consejo es empezar con Lovable, pero centrarse en proyectos más simples y directos, que aborden los problemas que desea resolver con la tecnología.
Sé un SaaS, uno Micro SaaS Ya sea una aplicación o una app, descubre cuál es el principal problema para el usuario final.
Es fundamental evitar el error de incluir desde el principio "un millón de características, un millón de métricas" y reglas de negocio complejas. Esto confunde al usuario y casi con seguridad provocará el fracaso del proyecto.
Centrarse en la creación en Amable Crea interfaces apps muy atractivas y visualmente atractivas. Primero soluciona el problema principal y solo entonces podrás hacer el proyecto más complejo.
Caso
Un ejemplo muy interesante, y uno de los principales casos de estudio de Lovable, es... Plink.
Básicamente, es una plataforma donde las mujeres pueden comprobar si su novio ha tenido algún problema con la policía o tiene antecedentes de agresión.
La creadora, Sabrina, se hizo famosa porque creó la aplicación sin saber nada de código, se centró en el problema principal y la aplicación simplemente "explotó".
En tan solo dos meses, el proyecto ya proyectaba ingresos de 2,2 millones de dólares. Ella validó la idea en Lovable, demostrando que el enfoque en el mercado es lo que determina el éxito de un proyecto.
Otro ejemplo es una aplicación de gestión de agentes de IA. Siempre comenzamos con la interfaz en Lovable y solo entonces migramos el proyecto a [la otra plataforma/herramienta]. Cursor para hacerlo más avanzado y complejo.
Master Supabase, el corazón de los proyectos avanzados.
El segundo consejo, y el más importante para la seguridad y la escalabilidad, es aprender a fondo el componente Supabase. Esto abarca el modelado de datos y todas las funciones de back-end.
Para crear proyectos de IA, necesitarás el front-end (la interfaz de usuario, como en Lovable) y el back-end (la inteligencia, los datos, la seguridad y la escalabilidad).
El back-end utiliza el N8N para la automatización y los agentes de IA, pero es el Supabase que será el corazón de tu proyecto.
Si quieres un proyecto altamente seguro y escalable, el secreto es dominar Supabase.
La gran ventaja es que, si la interfaz creada por Lovable tiene algún problema, como ya tienes el núcleo de tu proyecto bien estructurado, puedes simplemente eliminar Lovable y conectar los datos a otra interfaz, como Cursor.
No es necesario ser técnico, pero sí es necesario comprender... MacroCómo funcionan el modelado de datos, la seguridad (RLS) y la conexión de datos.
Comprender estos conceptos básicos es crucial para poder solicitar y gestionar la IA eficazmente. Para ello, recomiendo nuestro curso. Curso Supabase en la suscripción PRO.
Consejo 3: Cuándo pasar a editores de código basados en cursores o IA
El tercer consejo tiene que ver con dar el siguiente paso: migrar a herramientas y editores de código impulsados por IA, como... Cursor o Código de nube.
Es muy importante comenzar con Lovable de forma simplificada, pero si quieres hacer tu proyecto más avanzado, robusto y escalable, necesitarás combinar la organización de tu back-end en Supabase con el mayor control que ofrecen estas herramientas.
Sin embargo, es fundamental entender que conocer bien la Supabase Es un requisito previo antes de lanzarse a... Cursor, Porque necesitas tener la base de datos y la arquitectura muy bien organizada.
Para proyectos complejos, esta unión es clave para tener control total sobre el código y la estructura.
Conozca el Formación en codificación de IADomina la creación de mensajes, desarrolla agentes avanzados y lanza aplicaciones completas en tiempo récord.