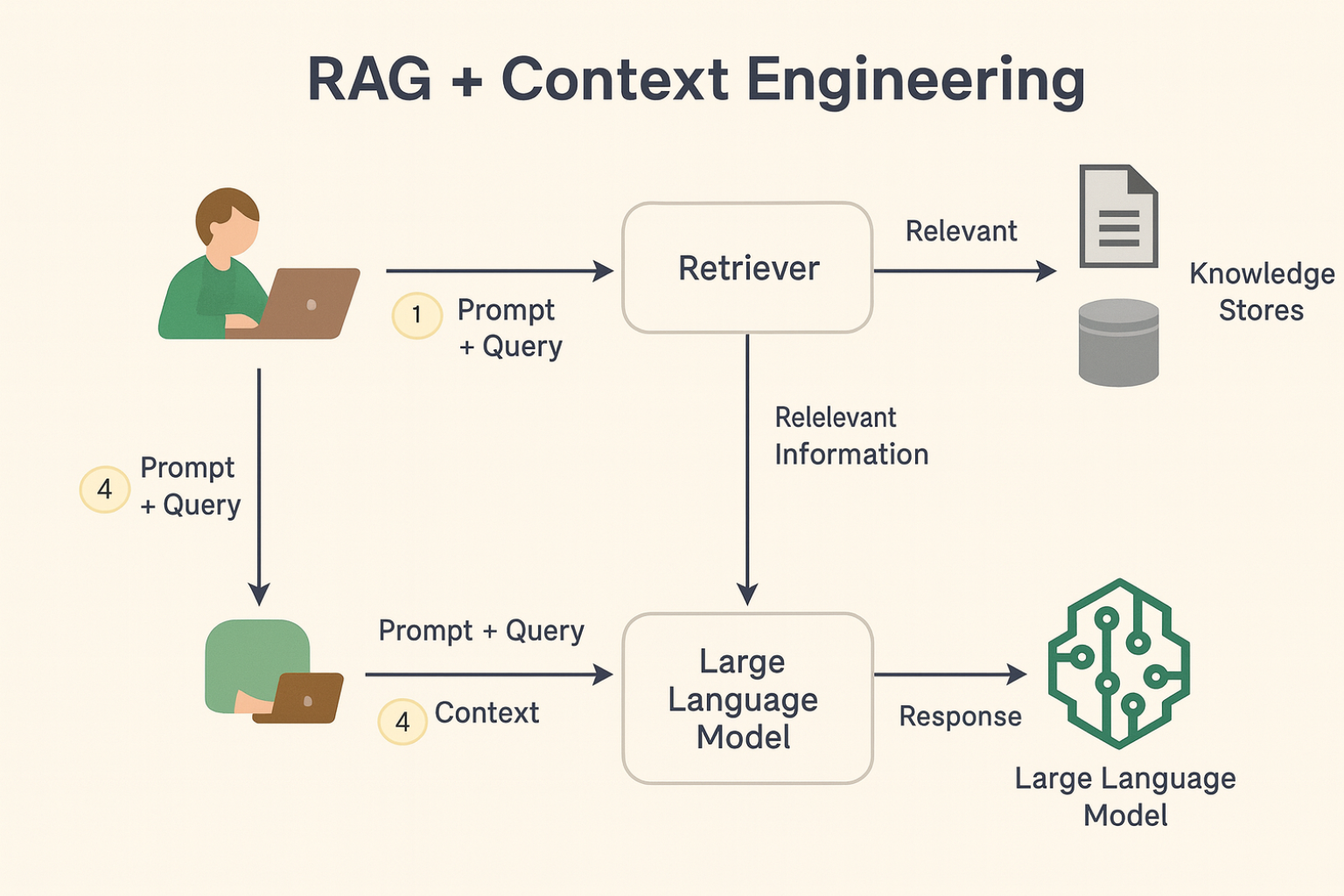
LlamaIndex es un marco de código abierto diseñado para conectar modelos de lenguaje grandes (LLM) a datos privados y actualizados que no están directamente disponibles en los datos de entrenamiento de los modelos.
La definición de Índice de llamas gira en torno a su función como intermediario entre el modelo de lenguaje y las fuentes de datos estructuradas y no estructuradas. Puede acceder a documentación oficial para obtener una visión detallada de sus características técnicas.

LlamaIndex ¿para qué sirve?
Integración con LLM
LlamaIndex es una herramienta desarrollada para facilitar la integración entre modelos de lenguaje grandes (LLM) y fuentes de datos externas que no son directamente accesibles al modelo durante la generación de respuestas.
Esta integración se produce a través del paradigma conocido como RAG (Generación Aumentada de Recuperación), que combina técnicas de recuperación de datos con generación de lenguaje natural.
Aplicaciones prácticas
La explicación simple de LlamaIndex radica en su utilidad: transforma documentos, bases de datos y fuentes diversas en conocimiento estructurado, listo para ser consultado por una IA.
Al hacerlo, resuelve una de las mayores limitaciones de los LLM: la imposibilidad de acceder a información actualizada o privada sin reconfiguración.
El uso de LlamaIndex con IA amplía los casos de aplicación de la tecnología, desde asistentes legales hasta bots de servicio al cliente y motores de búsqueda internos.
Limitaciones resueltas
LlamaIndex resuelve una limitación fundamental de los LLM: la dificultad de acceder a datos en tiempo real, actualizados o privados.
Al funcionar como una capa de memoria externa, conecta modelos de lenguaje a fuentes como documentos, hojas de cálculo, bases de datos SQL y API, sin la necesidad de ajustar los pesos de los modelos.
Su amplia compatibilidad con formatos como PDF, CSV, SQL y JSON lo hace aplicable a una variedad de industrias y casos de uso.
Esta integración se basa en el paradigma RAG (Recuperación-Generación Aumentada), que combina la recuperación de información con la generación de lenguaje natural, permitiendo al modelo consultar datos relevantes en el momento de la inferencia.
Como marco, LlamaIndex estructura, indexa y pone estos datos a disposición para que modelos como ChatGPT puedan acceder a ellos dinámicamente.
Esto permite que tanto los equipos técnicos como los no técnicos desarrollen soluciones de IA con mayor agilidad, menores costos y sin la complejidad de entrenar modelos desde cero.
¿Cómo utilizar LlamaIndex con modelos LLM como ChatGPT?
Consulte también el Entrenamiento N8N para automatizar flujos con herramientas no-code en proyectos de IA.
Pasos de uso
Capacitación de agentes y administradores de automatización con IA Se recomienda para aquellos que quieran aprender a aplicar estos conceptos de forma práctica, especialmente en el desarrollo de agentes autónomos basados en IA generativa.
La integración de LlamaIndex con LLM como ChatGPT implica tres pasos principales: ingesta de datos, indexación y consulta. El proceso comienza con la recopilación y transformación de los datos a un formato compatible con el modelo.
Estos datos se indexan en estructuras vectoriales que facilitan la recuperación semántica, lo que permite a LLM consultarlos durante la generación de texto. Finalmente, la aplicación envía preguntas al modelo, que responde en función de los datos recuperados.
Para conectar LlamaIndex a ChatGPT, el enfoque habitual consiste en usar las bibliotecas de Python disponibles en el repositorio oficial. La ingesta se puede realizar con lectores como SimpleDirectoryReader (para PDF) o CSVReader, y la indexación con VectorStoreIndex.
Ejemplo práctico: creación de un agente de IA con documentos locales
Analicemos un ejemplo práctico sobre cómo usar LlamaIndex para crear un agente de IA que responda preguntas basadas en un conjunto de documentos PDF locales. Este ejemplo ilustra con más detalle los pasos de ingesta, indexación y consulta.
1 – Preparación del entorno: Asegúrate de tener instalado Python y las bibliotecas necesarias. Puedes instalarlas mediante pip: bash pip install llama-index pypdf
2 – Ingestión de datos: Imagina que tienes una carpeta llamada mis_documentos que contiene varios archivos PDF. SimpleDirectoryReader de LlamaIndex facilita la lectura de estos documentos.

En este paso, SimpleDirectoryReader lee todos los archivos compatibles (como PDF, TXT, CSV) de la carpeta especificada y los convierte en objetos de documento que LlamaIndex puede procesar.
3 – Indexación de datos: Tras la ingesta, es necesario indexar los documentos. La indexación implica convertir el texto de los documentos en representaciones numéricas (incrustaciones) que capturan el significado semántico.
Estas incrustaciones se almacenan luego en un Índice de tienda de vectores. python # Crea un índice vectorial a partir de documentos # De forma predeterminada, utiliza incrustaciones de OpenAI y un VectorStore simple en memoria. índice = VectorStoreIndex.from_documents(docs) VectorStoreIndex es la estructura de datos principal que permite a LlamaIndex realizar búsquedas eficientes de similitud semántica.
Cuando se realiza una consulta, LlamaIndex busca los extractos más relevantes en los documentos indexados, en lugar de realizar una simple búsqueda de palabras clave.
4 – Generación de consultas y respuestas: Con el índice creado, ahora puedes realizar consultas. as_query_engine() crea un motor de consultas que interactúa con el LLM (como ChatGPT) y el índice para proporcionar respuestas basadas en sus datos.

- Cuando se llama a query_engine.query(), LlamaIndex hace lo siguiente:
- Convierte tu pregunta en una incrustación.
- Utilice esta incrustación para encontrar los extractos más relevantes en documentos indexados (Recuperación).
- Envíe estos extractos relevantes, junto con su pregunta, a LLM (Generación).
- LLM luego genera una respuesta basada en el contexto proporcionado por sus documentos.
Este flujo demuestra cómo LlamaIndex actúa como un puente, permitiendo a LLM responder preguntas sobre sus datos privados, superando las limitaciones del conocimiento previamente entrenado del modelo.

Casos de uso detallados
LlamaIndex, al conectar los LLM con datos privados en tiempo real, abre un amplio abanico de aplicaciones prácticas. Exploremos dos escenarios detallados para ilustrar su potencial:
- Asistente legal inteligente:
- Guión: Un bufete de abogados cuenta con miles de documentos legales, como contratos, jurisprudencia, opiniones y estatutos. Los abogados dedican horas a investigar información específica de estos documentos para preparar casos o brindar asesoramiento.
- Solución con LlamaIndex: LlamaIndex permite indexar toda la base de datos documental de la firma. Un programa de maestría en derecho (LLM), como ChatGPT, integrado con LlamaIndex, puede actuar como asistente legal.
Los abogados pueden hacer preguntas en lenguaje natural como “¿Cuáles son los precedentes legales para casos de disputas de tierras en áreas protegidas?” o “Resuma las cláusulas de rescisión del contrato X”.
LlamaIndex recuperaría los extractos más relevantes de los documentos indexados y LLM generaría una respuesta concisa y precisa, citando las fuentes. - Beneficios: Reducción drástica del tiempo de investigación, mayor precisión de la información, estandarización de las respuestas y liberación de los abogados para tareas de mayor valor estratégico.
- Chatbot de atención al cliente para comercio electrónico:
- Guión: Una tienda en línea recibe un gran volumen de preguntas repetitivas de los clientes sobre el estado de sus pedidos, las políticas de devolución, las especificaciones de los productos y las promociones. El soporte técnico está desbordado y los tiempos de respuesta son largos.
- Solución con LlamaIndex: LlamaIndex puede indexar las preguntas frecuentes de su tienda, los manuales de productos, las políticas de devolución, el historial de pedidos (anónimos) e incluso los datos de inventario.
Un chatbot impulsado por un Maestría en Derecho y LlamaIndex puede responder instantáneamente a preguntas como "¿Cuál es el estado de mi pedido #12345?", "¿Puedo devolver un producto después de 30 días?" o "¿Cuáles son las especificaciones del teléfono inteligente X?".
Beneficios: Soporte 24 horas al día, 7 días a la semana, reducción de la carga de trabajo del equipo de soporte, mejora de la satisfacción del cliente con respuestas rápidas y precisas, y escalabilidad del soporte sin aumentos de costos proporcionales.

¿Cuáles son las ventajas de LlamaIndex sobre otras herramientas RAG?
Una de las principales ventajas de LlamaIndex es su curva de aprendizaje relativamente sencilla. En comparación con soluciones como LangChain y Haystack, ofrece mayor simplicidad en la implementación de pipelines RAG, a la vez que mantiene la flexibilidad para personalizaciones avanzadas.
Su arquitectura modular facilita la sustitución de componentes, como sistemas de almacenamiento vectorial o conectores de datos, según lo dicten las necesidades del proyecto.
LlamaIndex también destaca por su compatibilidad con múltiples formatos de datos y su documentación clara. Su comunidad activa y su constante programa de actualizaciones convierten al framework en una de las mejores herramientas RAG para desarrolladores y startups.
En comparación entre las herramientas RAG, la LlamaIndex frente a Lang Chain Destaca diferencias significativas: mientras que LangChain es ideal para flujos complejos y aplicaciones orquestadas con múltiples pasos, LlamaIndex favorece la simplicidad y un enfoque en los datos como principal fuente de contextualización.
Para una comparación en profundidad, consulte Este informe técnico de Towards Data Science, que explora los escenarios de uso ideales para cada herramienta. Otra fuente relevante es el artículo RAG con LlamaIndex del blog oficial de LlamaHub, que analiza los puntos de referencia de rendimiento.
También te recomendamos el post Evaluación comparativa de tuberías RAG, que presenta pruebas comparativas con métricas objetivas entre diferentes marcos.

Comience a utilizar LlamaIndex en la práctica
Ahora que comprende la definición de LlamaIndex y los beneficios de integrarlo con modelos LLM como ChatGPT, puede comenzar a desarrollar soluciones de IA personalizadas basadas en datos reales.
El uso de LlamaIndex con IA no solo aumenta la precisión de las respuestas, sino que también abre nuevas posibilidades de automatización, personalización e inteligencia empresarial.
NoCode StartUp ofrece varias rutas de aprendizaje para profesionales interesados en aplicar estas tecnologías en el mundo real. Desde Entrenamiento de agentes con OpenAI hasta el Entrenamiento sin código de IA SaaSLos cursos cubren todo, desde conceptos básicos hasta arquitecturas avanzadas utilizando datos indexados.