¿Alguna vez has tenido una idea brillante que podría revolucionar tu campo de actividad, pero no sabes cómo convertirla en realidad sin gastar mucho dinero y recursos?
O MVP – Producto mínimo viable – es una estrategia que puede cambiar por completo la forma en que desarrolla productos e impulsa su startup.
O MVP Es la versión más simplificada de un producto o parte de él, creada con la menor cantidad de recursos posible.
Esta versión busca entregar la esencia de la idea y su principal propuesta de valor, con el objetivo de validar si la idea es realmente interesante y si merece la pena invertir más recursos en ella.
En este artículo, exploraremos el significado y la importancia de MVP para su startup. Para aquellos que quieren Haz dinero en línea, conocer este método es fundamental.
¡Sigue leyendo para comprender mejor y comenzar a implementar esta estrategia en tu startup hoy!
Tabla de contenido
¿Qué es MVP?
MVP es el acrónimo de Producto mínimo viable en ingles y significa Producto mínimo viable en portugués.
Como su nombre lo indica, se trata de una práctica que consiste en crear una versión de prueba del producto, con sólo las funcionalidades mínimas necesarias para que cumpla su función.
A partir de esta prueba, es posible observar en la práctica la Eficiencia del producto, usabilidad y aceptación en el mercado..
También permite comparar la competencia, obtención de asociaciones y atracción de inversores.
Si el producto tiene éxito en esta etapa, se desarrolla y mejora nuevamente antes de llegar oficialmente al mercado.
Ahora, piensa por un momento: ¿Cuántas veces has tenido una idea que parecía increíble, pero cuando la pusiste en práctica no generó el retorno esperado? Esto es exactamente lo que el MVP busca evitar.
En lugar de pasar meses o incluso años desarrollando un producto completo, crea un MVP para probar el mercado, recopilar comentarios de usuarios reales y realizar los ajustes necesarios.
¿Cuáles son los tipos de MVP más utilizados?
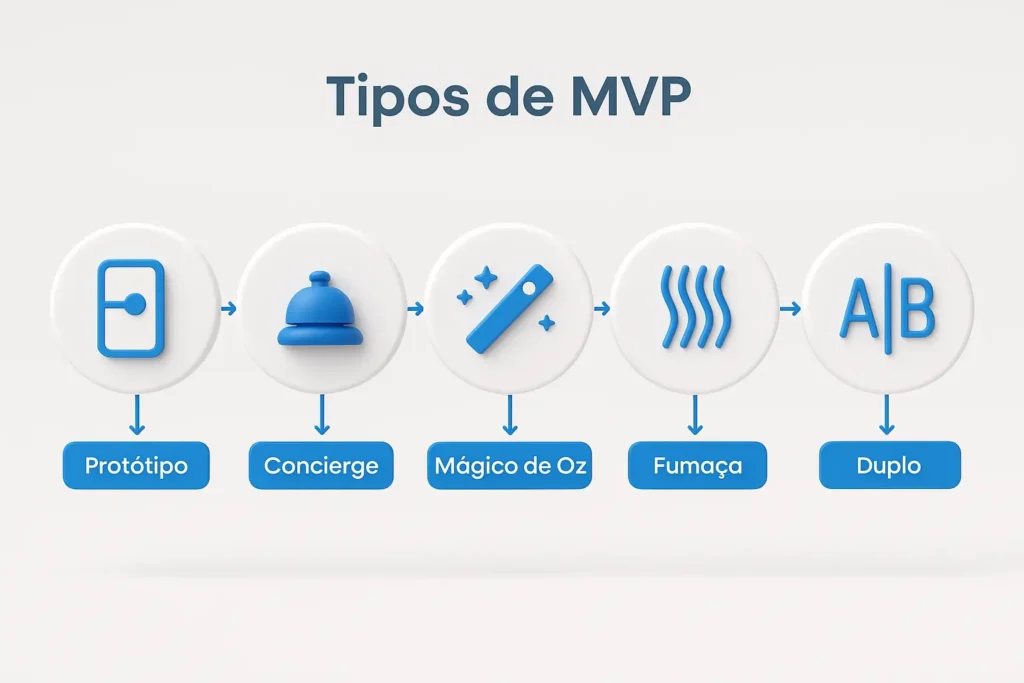
Existen varios tipos de MVP, cada uno con sus características y enfoques específicos. Exploremos algunos de los más conocidos:
Prototipo
El jugador más valioso Prototipo se utiliza a menudo para productos fisicos, por ejemplo: teléfonos inteligentes, automóviles, electrónicos, entre otros.
En esta aplicación se crea una versión simplificada del producto, que puede ser un ejemplo real o simulado, para ser sometido a pruebas de usuario.
Este tipo de MVP es ideal para obtener comentarios detallados sobre la interacción del usuario con el producto.
Doble
Ya el MVP Doble consiste en crear dos versiones similares del producto, se prueban simultáneamente utilizando el Metodología A/B.
Este enfoque permite comparar resultados y elegir la versión que mejor se adapte a las necesidades de los usuarios, ayudando a optimizar la inversión.
Fumar
A su vez, el MVP Fumar Se realiza con la intención de evaluar el interés de los clientes potenciales en el producto o servicio. Es posible poner en práctica esta estrategia a través de un página de destino, por ejemplo.
En este espacio la empresa puede hablar de sus conceptos y operaciones y estimular el interés de los usuarios.
A partir de esta interacción, se puede medir la tasa de conversión de la página y tener una idea más realista sobre el producto.
Mago de Oz
En MVP Mago de Oz, los clientes interactúan con una interfaz de producto simulada, creyendo que están utilizando una solución automatizada. Sin embargo, entre bastidores, las acciones se realizan manualmente.
Este tipo de MVP permite probar la viabilidad de la idea, sin necesidad de desarrollar una solución completamente automatizada.
Conserje
El jugador más valioso Conserje es una estrategia en la que el propio empresario realiza el servicio manualmente, ofreciendo atención personalizada a los clientes.
Aunque tiene una escalabilidad limitada, es excelente para validar la demanda y comprender las necesidades del usuario directamente.
¿Cuál es el mejor tipo de MVP?
Para responder a esta pregunta, en primer lugar hay que analizar la recursos que tiene el proyecto. Cada tipo de MVP tiene unos requisitos diferentes, y esto hay que tenerlo en cuenta.
El segundo elemento a analizar debe ser el producto o servicio que se está probandoPor ejemplo, si estás desarrollando un coche, es esencial realizar pruebas de prototipos.
Pero si estás construyendo una red social, el MVP del Mago de OZ podría ser justo lo que necesitas.
¡A continuación te guiaremos paso a paso a la hora de poner en práctica el MVP!

¿Cómo desarrollar un MVP?
Ahora que comprende los tipos de MVP, exploremos el proceso de creación de un MVP eficaz. Mira el paso a paso:
Identificar el problema
El primer paso para crear un MVP exitoso es identificar claramente el problema que resolverá su producto. Comprender los dolores y necesidades de su público objetivo es crucial.
Por lo tanto, céntrate en estos dos pasos:
- Comprender el dolor y las necesidades: Analice el mercado e identifique las dificultades que enfrenta su audiencia. Esto garantizará que su MVP satisfaga la demanda real.
- Definición de personas: Cree clientes ideales que representen a su público objetivo. Vaya más allá de la demografía y explore los problemas específicos que enfrentan.
No dudes en dedicar mucho tiempo a este paso inicial, ya que es lo que dictará la calidad de tu servicio y lo que hay que analizar en cada prueba.
Analizar la competencia
Antes de continuar, es importante comprender el panorama competitivo en el que se lanzará su producto. Por lo tanto, estudie a los competidores que ofrecen soluciones similares.
Identifique sus fortalezas, debilidades y enfoques de mercado. y cómo abordar mejor cada uno de estos puntos.
Identificar brechas en las ofertas de la competencia. ¿Qué puede ofrecer su producto que sea único y mejor?
Idealizar el producto
Ahora que entiendes el problema, es hora de idear cómo tu producto resolverá esta demanda de manera innovadora.
En este punto, es importante especificar las características y funcionalidades del producto y determinar cómo satisfará las necesidades de las personas.
Además, es necesario establecer la propuesta de valor del producto. Pregúntese: ¿Cómo se diferencia de la competencia? ¿Por qué las personas elegirían su producto?
Considere la demanda
Evaluar la demanda de su producto es esencial para garantizar que su MVP tenga potencial de aceptación.
Por lo tanto, llevar a cabo prueba de aceptacion como encuestas y sondeos para evaluar la receptividad del mercado al concepto de su producto.
Además, crear páginas de destino o utilizar otras estrategias para capturar dirige y evaluar el interés real de las personas.
Usar programación en código
En la etapa de desarrollo de MVP, puede explorar las ventajas de no-code herramientas, que ofrecen un enfoque visual y simplificado para la creación de aplicaciones y software.
Estas herramientas permiten desarrollar prototipos y productos funcionales sin necesidad de conocimientos profundos de programación.
A continuación se muestran algunas ventajas de las herramientas no-code aplicadas al proceso de creación de MVP:
- Desarrollo rápido;
- Creación de prototipos iterativos;
- Reducción de costos;
- Mayor autonomía;
- Integración de datos;
- Validación de conceptos;
- Flexibilidad de diseño.
Algunas de las herramientas no-code disponibles incluyen Webflow, WordPress, Bubble, Imagen, Suave, AppGyver, FlutterFlow, Glide, Xano, Airtable, Zapier y Make.
Descubre cuál es el código haciendo clic aquí.
Construir, probar y mejorar
Con el MVP listo, desarrollelo según lo planeado, manteniéndolo simple y enfocado en resolver el problema. Realizar pruebas rigurosas con un grupo inicial de usuarios, recopilar y evaluar comentario.
Según los comentarios de los usuarios, realice mejoras en el MVP, agregando las funciones necesarias y ajustando las debilidades.
Si sigue estos pasos, desde la identificación del problema hasta la iteración continua, creará un MVP sólido, allanando el camino hacia un producto exitoso y competitivo.
Importancia del MVP para startups
Ahora que comprende cómo crear y desarrollar un MVP, puede comprender por qué es tan importante para garantizar el éxito de cualquier startup.
MVP le permite probar su idea en el mercado real antes de invertir importantes recursos. Este proceso evita gastos innecesarios en productos que pueden no satisfacer las necesidades de los usuarios.
Además, con un MVP en la mano, puedes recolectar comentario directamente de los usuarios, identificando fortalezas, debilidades y oportunidades de mejora.
Esto guía el desarrollo futuro, garantizando que su solución evolucione de acuerdo con las expectativas del cliente.
Entonces, si estás a punto de lanzar una startup o desarrollar un nuevo producto, MVP es tu camino ideal.
Empieza ahora mismo
¡Para poner en práctica el desarrollo de un MVP, puedes contar con los cursos gratuitos de No-Code Startup!
Como Curso FlutterFlowAprenderás a crear aplicaciones para iOS y Android, sin necesidad de escribir código.
Es una excelente manera de aplicar un MVP del Mago de Oz, por ejemplo. No se requieren conocimientos previos y todas las lecciones son gratuitas.
Ahora, si prefieres dominar la creación de software y aplicaciones web para implementar tu MVP, el curso de burbujas destaca como la mejor opción.
Además de ser gratuito, ofrece la base necesaria para iniciar tus estudios en el área de programación.