Tiempo estimado de lectura: 7 minutos
Crear una aplicación de IA es uno de los esfuerzos más emocionantes y transformadores en el mundo del desarrollo de aplicaciones. Y hay una buena razón para ello.
La IA puede mejorar la idea de su aplicación al ofrecer a los usuarios una experiencia mejorada a través de automatización inteligente y funciones intuitivas.
Si estás ansioso por crear una aplicación impulsada por IA pero no sabes por dónde empezar, estás en el lugar correcto. Esta guía lo guiará a través de todo el proceso, desde el establecimiento de sus objetivos hasta la implementación final.
1. Establece objetivos para tu aplicación de IA

Antes de sumergirse en el desarrollo, el paso más importante es definir objetivos claros para su aplicación de IA.
Sus objetivos sirven como una hoja de ruta, manteniendo su proceso de desarrollo encaminado y garantizando que todos los involucrados estén alineados con su visión.
Comience por definir el problema central que su aplicación resolverá para sus usuarios.
Por ejemplo, el objetivo de Grammarly es sencillo: proporcionar correcciones gramaticales y de estilo en tiempo real para mejorar la escritura de los usuarios.
Esta claridad garantiza que cada aspecto del desarrollo de la aplicación permanezca enfocado y orientado a un propósito.
Una vez definido su objetivo principal, es momento de establecer indicadores clave de rendimiento (KPI) para medir el éxito de su aplicación de IA.
Sus KPI deben seguir el marco SMART (específico, medible, alcanzable, relevante y limitado en el tiempo).
Además, establezca hitos claros de desarrollo e implementación para mantener su proyecto encaminado.
Esto se vuelve mucho más fácil si su equipo sigue un enfoque de desarrollo ágil como Scrum, que promueve un progreso rápido e iterativo.
No olvide evaluar sus recursos, asegurándose de que su infraestructura pueda manejar las demandas de capacitación y mantenimiento de modelos de IA, tareas que a menudo consumen una cantidad significativa de potencia informática.
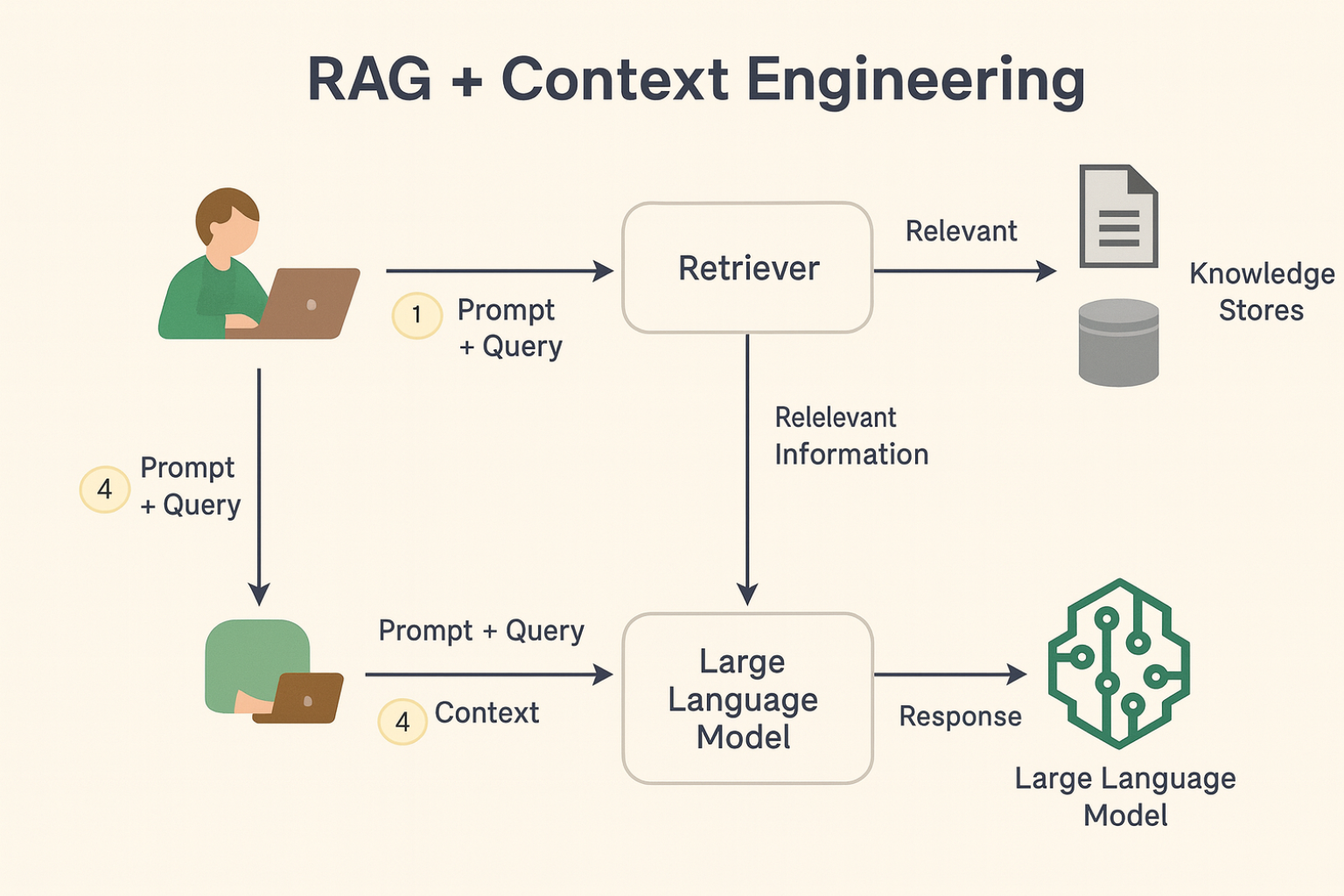
2. Elija las herramientas y marcos adecuados
El éxito de su aplicación de IA se puede lograr con la mejores herramientas NoCode, que permite la creación de soluciones robustas sin necesidad de codificación avanzada.
Estas plataformas democratizan el acceso a la IA al ofrecer interfaces intuitivas y automatizar procesos complejos de desarrollo y entrenamiento de modelos.
Algunas de las herramientas NoCode más populares son:
- Bubble: Una poderosa plataforma para crear aplicaciones web sin codificación. Con integraciones para IA y automatización, le permite desarrollar soluciones personalizadas y escalables con facilidad.
- hacer integromat: Ideal para automatizar flujos de trabajo y conectar diferentes servicios. En el caso de la IA, se puede utilizar para procesar datos e integrar herramientas de aprendizaje automático, simplificando tareas complejas.
- flujo de aleteo: Una plataforma enfocada a la creación de aplicaciones móviles de forma rápida e intuitiva. Basado en Flutter, permite a los usuarios desarrollar aplicaciones para Android e iOS sin necesidad de codificación compleja, además de ofrecer capacidades de integración con IA, automatización y bases de datos, permitiendo la creación de soluciones robustas.
Además, plataformas como Google Cloud AutoML y Azure AI ofrecen interfaces NoCode para equipos que necesitan soluciones de IA sin tratar directamente con el código.
3. Recopilar y preparar datos
Los datos son el combustible que impulsa su aplicación de IA y la calidad de sus datos determina el rendimiento de su modelo. Siempre se deben priorizar los datos de alta calidad sobre la cantidad.
Comience por seleccionar los conjuntos de datos adecuados para su modelo de IA. Los conjuntos de datos públicos suelen ser un excelente punto de partida.
Por ejemplo, Common Crawl es un gran repositorio abierto de datos web y plataformas como Kaggle y Intercambio de datos de AWS Ofrecemos una variedad de conjuntos de datos para necesidades específicas.
Una vez que haya reunido sus conjuntos de datos, es necesario limpiarlos, preprocesarlos y organizarlos en un formato adecuado para entrenar su modelo.
Al encargarse de la recopilación y preparación de datos, sentará una base sólida para desarrollar un modelo de IA eficaz.
4. Diseñe y entrene su modelo para la aplicación de IA
Con sus datos listos, el siguiente paso es diseñar y entrenar su modelo de IA. El modelo es el núcleo de su aplicación de IA, por lo que es esencial realizar este paso correctamente.
Primero, elija el enfoque de capacitación adecuado según las necesidades de su proyecto. Las principales opciones son:
- Aprendizaje supervisado: ideal para tareas en las que hay datos etiquetados disponibles, como el reconocimiento de imágenes.
- Aprendizaje no supervisado: Adecuado para tareas más dinámicas como sistemas de recomendación.
- Aprendizaje por refuerzo: ideal para modelos que necesitan aprender a través de retroalimentación, como los modelos de procesamiento del lenguaje natural (NLP).
A continuación, elija la arquitectura de su modelo; las opciones populares son redes neuronales convolucionales (CNN), redes neuronales recurrentes (RNN) o redes generativas adversarias (GAN), según la tarea en cuestión.
Después del entrenamiento, evalúe el rendimiento de su modelo utilizando los KPI que definió anteriormente. Si todo parece correcto, está listo para integrar el modelo en su aplicación.
5. Integre el modelo de IA en su aplicación
La integración del modelo de IA es un paso fundamental en el desarrollo de su aplicación.
Aquí es donde su modelo de IA pasa de la teoría a la práctica, aprovechando las capacidades en tiempo real con las que interactuarán los usuarios.
Decida si el modelo de IA se ejecutará en el front-end o en el back-end de su aplicación, según su propósito. También deberá elegir entre procesamiento basado en la nube o en el dispositivo.
Por último, asegúrese de que su aplicación incluya un circuito de retroalimentación que permita a los usuarios proporcionar información sobre el rendimiento de la IA, lo que le ayudará a refinar y mejorar el modelo con el tiempo.
6. Pruebe y optimice: mejore su proceso de desarrollo

Incluso después de la implementación, su aplicación de IA es un trabajo en progreso.
Los modelos de IA deben entrenarse y mejorarse periódicamente a medida que hay nuevos datos disponibles para evitar desviaciones del modelo y mantener el funcionamiento óptimo de la aplicación.
Las fases clave de prueba incluyen:
- Pruebas unitarias: garantiza que los componentes individuales de su aplicación funcionen como se espera.
- Pruebas de integración: prueba cómo interactúa el modelo de IA con otros componentes.
- Pruebas de aceptación del usuario: involucra a usuarios reales para garantizar que su aplicación de IA satisfaga sus necesidades.
Por lo tanto, al probar y perfeccionar continuamente su aplicación, la mantendrá relevante y funcional a largo plazo.
Desarrollar una aplicación de IA puede llevar su software al siguiente nivel, ofreciendo funciones de vanguardia que los usuarios adorarán. Sin embargo, el proceso de desarrollo requiere una planificación y ejecución cuidadosa.
Siga esta guía paso a paso y estará bien encaminado para crear una aplicación de IA que se destaque en el competitivo panorama tecnológico.
Entonces, si está listo para hacer realidad su idea de aplicación de IA, ¡déjenos ayudarlo! Ven y sé parte de Formación NoCodeIA.