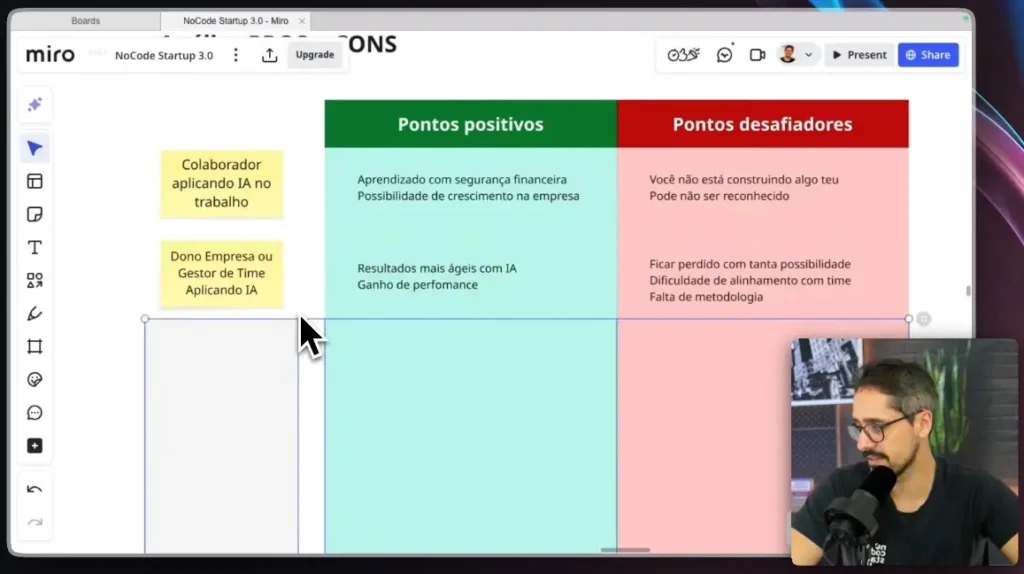
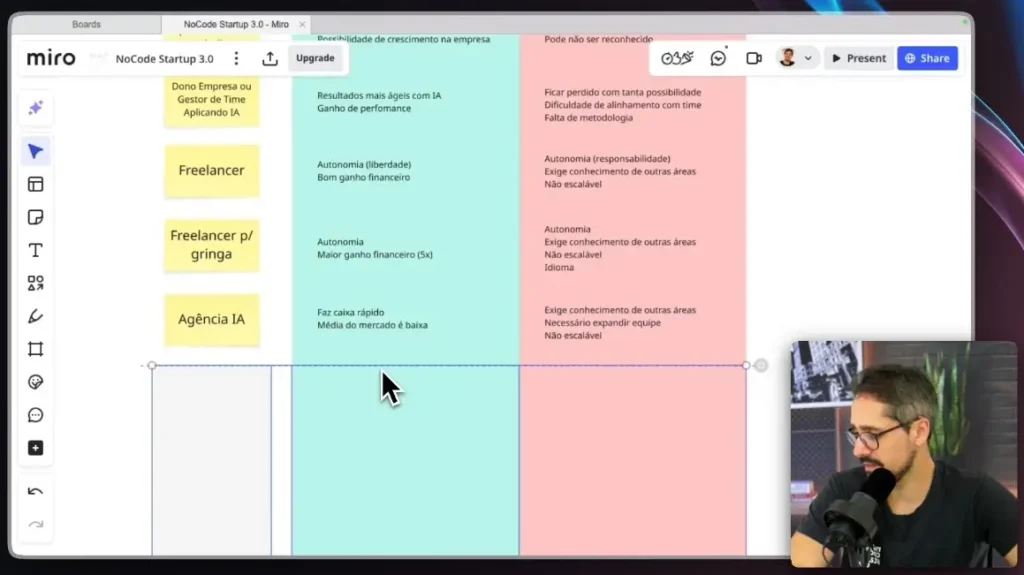
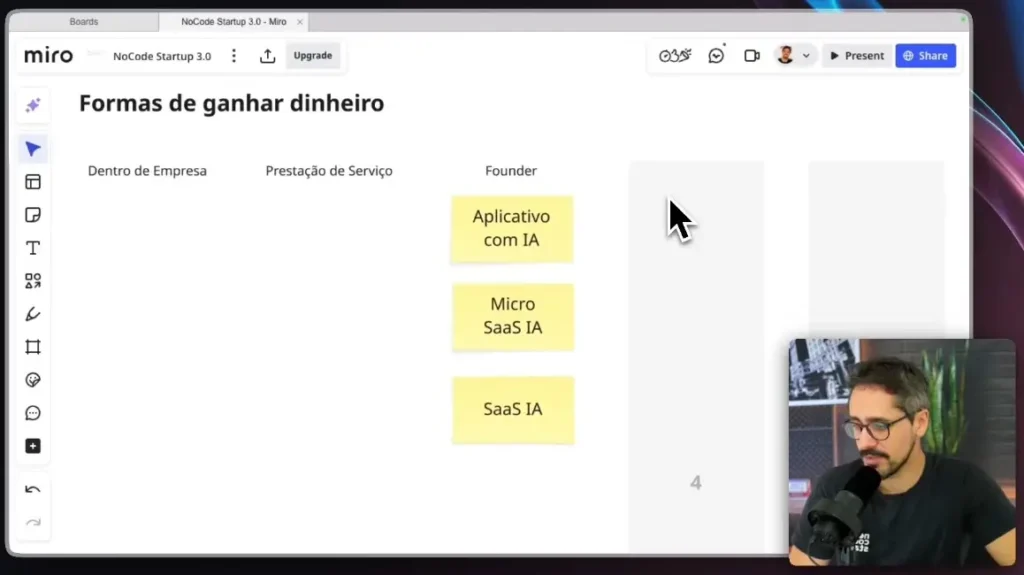
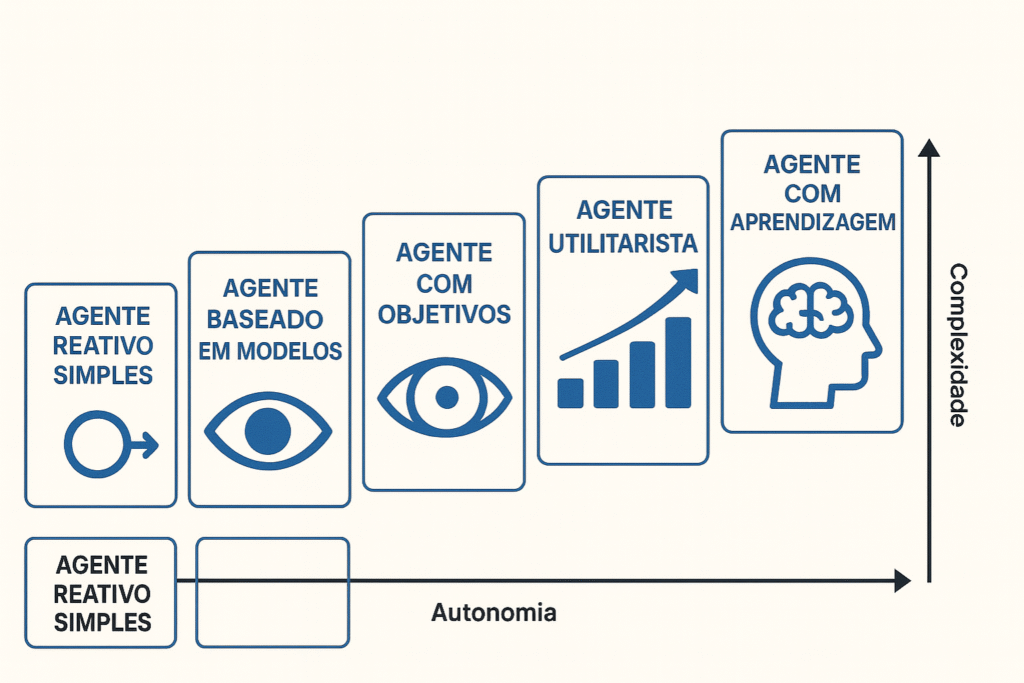
Imagine que você tem um assistente superinteligente treinado com base em todo o conhecimento disponível na internet. No entanto, quando se trata de informações específicas do seu negócio, ele pode não ter referências diretas. Dessa forma, como resolver essa limitação?
Uma das formas mais eficazes de aprimorar a inteligência do seu assistente é treiná-lo com dados personalizados, como documentos, artigos e arquivos internos.
Essa técnica é conhecida como RAG (Retrieval-Augmented Generation) e permite que assistentes de IA combinem conhecimento pré-existente com informações específicas para fornecer respostas mais precisas e úteis.
Continue a leitura para entender melhor como essa abordagem pode transformar o uso da IA no seu negócio.
Conteúdo
Como funciona o RAG (Retrieval-Augmented Generation)?

Agora que entendemos o conceito de RAG (Retrieval-Augmented Generation), vamos explorar seu funcionamento em detalhes.
Diferente de assistentes de IA tradicionais que apenas geram respostas com base no conhecimento previamente treinado, o RAG busca informações em fontes externas e combina esses dados com seu conhecimento prévio para fornecer respostas mais precisas e relevantes.
O processo pode ser dividido em três etapas principais:
Pergunta ao modelo de IA
O usuário faz uma pergunta ao assistente de IA, assim como faria no ChatGPT ou em outro chatbot tradicional.
Busca de informações (Retrieval)
O assistente de IA consulta uma base de dados específica, como PDFs, sites, documentos internos ou um banco de conhecimento do negócio. Ele recupera as informações mais relevantes para responder à pergunta.
Geração aumentada (Augmented Generation)
Com os dados recuperados, a IA refina e estrutura a resposta, combinando informações do banco de conhecimento com seu próprio modelo linguístico. Isso garante uma resposta contextualizada, precisa e relevante.
Esse método é altamente eficiente, uma vez que permite que a IA forneça respostas mais personalizadas com base em dados internos. Além disso, a tecnologia pode utilizar documentação de produtos, bases de conhecimento de suporte e, até mesmo, políticas empresariais para garantir informações precisas e relevantes.

No entanto, diferentemente de um chatbot convencional, que responde com base apenas em seu treinamento original, um modelo RAG pode ser atualizado constantemente com novas informações, sem que seja necessário um novo treinamento massivo.
Ou seja, isso permite que a IA seja altamente dinâmica e evolua progressivamente conforme novos conteúdos são adicionados, garantindo maior precisão e relevância nas respostas.
Por exemplo, dentro da comunidade NoCode, disponibilizamos assistentes que utilizam RAG para responder dúvidas sobre ferramentas como Make, Dify, N8N e Bubble.
Além disso, esses assistentes foram treinados com documentação específica dessas plataformas, o que permite que forneçam respostas ainda mais detalhadas e precisas para os alunos, facilitando assim o aprendizado e a resolução de dúvidas técnicas.
5 Benefícios do uso do RAG

Agora que você já entende como o RAG funciona, vamos explorar os principais benefícios que essa tecnologia pode trazer para empresas e usuários:
1. Respostas mais precisas e contextualizadas
O RAG permite que assistentes de IA consultem informações atualizadas em tempo real, tornando as respostas mais relevantes e detalhadas.
2. Automação e eficiência
Com a capacidade de acessar bases de conhecimento específicas, a IA reduz a necessidade de suporte humano constante, otimizando tempo e recursos.
3. Aprendizado contínuo sem necessidade de retreinamento
Diferente de modelos de IA tradicionais, que precisam ser constantemente treinados e retreinados para aprender novas informações, o RAG pode simplesmente consultar bases de dados atualizadas.
4. Personalização para diferentes negócios
Empresas podem adaptar a IA para responder dúvidas específicas do seu setor, treinando o assistente com manuais técnicos, bases de conhecimento internas e outros documentos relevantes.
5. Aplicação do RAG no suporte ao cliente
Além do uso acadêmico e educacional, empresas de diversos setores estão utilizando o RAG para melhorar o suporte ao cliente.
Imagine uma empresa de tecnologia que vende softwares complexos. Os clientes frequentemente entram em contato com o suporte para esclarecer dúvidas sobre funcionalidades específicas.
Com um assistente de IA treinado com RAG, a empresa pode alimentar a IA com sua base de conhecimento interna, manuais técnicos e FAQs. Desse modo, o agente é capaz de responder dúvidas com precisão e agilidade, o que contribui para reduzir a necessidade de intervenção humana e otimizar o suporte ao cliente.
Como aplicar o RAG no seu negócio?
Empresas de diferentes segmentos podem aproveitar essa tecnologia para melhorar processos internos, atendimento ao cliente e automação de tarefas. A seguir, confira algumas estratégias práticas para aplicar o RAG no seu negócio.
1. Identifique as principais necessidades da sua empresa
Antes de integrar o RAG, avalie quais áreas do seu negócio podem se beneficiar dessa tecnologia. Faça-se as seguintes pergunta:
- o suporte ao cliente recebe muitas perguntas repetitivas?
- sua equipe precisa acessar documentos técnicos frequentemente?
- existe uma grande base de dados que poderia ser melhor aproveitada?
- o treinamento interno poderia ser otimizado com um assistente IA?
2. Escolha as fontes de dados corretas
O grande diferencial do RAG é sua capacidade de buscar informações em fontes externas. Para garantir respostas precisas e confiáveis, é fundamental selecionar os melhores repositórios de dados. Algumas opções incluem:
- documentação técnica e manuais de produtos;
- faqs e bases de conhecimento internas;
- artigos, pesquisas e estudos de caso;
- dados estruturados de CRMS e ERPS;
- arquivos em pdf, planilhas e notion.
3. Integre o RAG às suas ferramentas existentes
Para obter melhores resultados, o RAG deve estar conectado às plataformas que sua equipe já utiliza. Algumas formas de integração incluem:
- Chatbots e assistentes virtuais: IA treinada para responder dúvidas recorrentes e fornecer suporte técnico;
- Sistemas de gestão (CRM/ERP): a IA pode acessar dados do cliente para fornecer respostas mais personalizadas;
- E-learning e treinamento corporativo: assistentes inteligentes que ajudam funcionários a acessar materiais de aprendizado rapidamente;
- E-commerce e atendimento ao cliente: chatbots que consultam estoque, política de devolução e recomendações de produtos.
4. Avalie e otimize
A implementação do RAG não termina na configuração inicial. É essencial monitorar o desempenho da IA, analisando métricas como:
- taxa de acerto das respostas;
- satisfação dos usuários;
- redução do tempo de atendimento;
- dúvidas mais frequentes e oportunidades de melhoria.
Com essas informações, você pode aprimorar o banco de dados da IA e garantir que as respostas fiquem cada vez mais precisas.
Próximos Passos
Seja para melhorar o suporte ao cliente, automatizar processos ou otimizar a gestão de conhecimento interno, o RAG é uma solução poderosa e acessível para empresas de diferentes segmentos.
Com essa tecnologia, agentes de IA podem acessar bases de conhecimento específicas, aprimorar a experiência do usuário e reduzir a necessidade de treinamentos extensivos.
Se você deseja aprender a criar assistentes de IA inteligentes utilizando N8N, conheça o curso completo da NoCode Startup. Nele, você terá acesso a um treinamento prático sobre automação e integração de dados para tornar a IA do seu negócio ainda mais eficiente.
Explore mais sobre o Curso N8N – NoCode Startup e comece a transformar a sua empresa com inteligência artificial!