Atualmente, criar aplicativos escaláveis e seguros requer uma infraestrutura de backend robusta. No entanto, para muitos desenvolvedores, gerenciar as complexidades de servidores, sistemas de autenticação e armazenamento pode ser uma tarefa complexa. É aqui que o Supabase entra em cena.
O Supabase é uma plataforma de Backend as a Service (BaaS) que oferece autenticação, banco de dados PostgreSQL, APIs automáticas e edge functions prontas para uso.
Ele é considerado por muitos como a alternativa de código aberto ao Firebase, mas com recursos avançados para quem precisa escalar projetos de forma profissional.
Neste guia, exploraremos tudo o que você precisa saber sobre o Supabase, seus principais recursos e como ele pode ajudar os desenvolvedores a otimizar seu fluxo de trabalho.
O que é o Supabase?
O Supabase é uma alternativa poderosa e de código aberto ao Firebase, oferecendo um banco de dados PostgreSQL gerenciado.
De forma a combinar recursos em tempo real, autenticação de usuário, armazenamento de arquivos e até mesmo funções sem servidor.
A plataforma foi projetada com o objetivo de simplificar o desenvolvimento de backend, ao mesmo tempo em que fornece a escalabilidade e segurança.
Ao contrário dos backends tradicionais, o Supabase lida com grande parte do trabalho pesado, oferecendo um backend gerenciado com configuração mínima.
Os desenvolvedores podem se concentrar na construção de seus aplicativos frontend enquanto aproveitam os recursos de backend do Supabase por meio de uma API.

Por que escolher o Supabase?
O principal apelo do Supabase está em sua capacidade de fornecer aos desenvolvedores um backend robusto que não requer configuração ou gerenciamento complexo. Tradicionalmente, os desenvolvedores teriam que lidar com diversas configurações separadamente.
O Supabase reúne todos esses recursos em um pacote coeso, reduzindo a necessidade de fazer malabarismos com vários serviços e ferramentas. Outro benefício significativo é sua natureza de código aberto.
Enquanto o Firebase é um ecossistema fechado com tecnologia proprietária, o Supabase é construído com as melhores ferramentas de código aberto, principalmente PostgreSQL.
Isso significa que você obtém a flexibilidade e a transparência do software de código aberto sem sacrificar os benefícios de um serviço gerenciado.
Agora, vamos nos aprofundar nos principais recursos do Supabase.
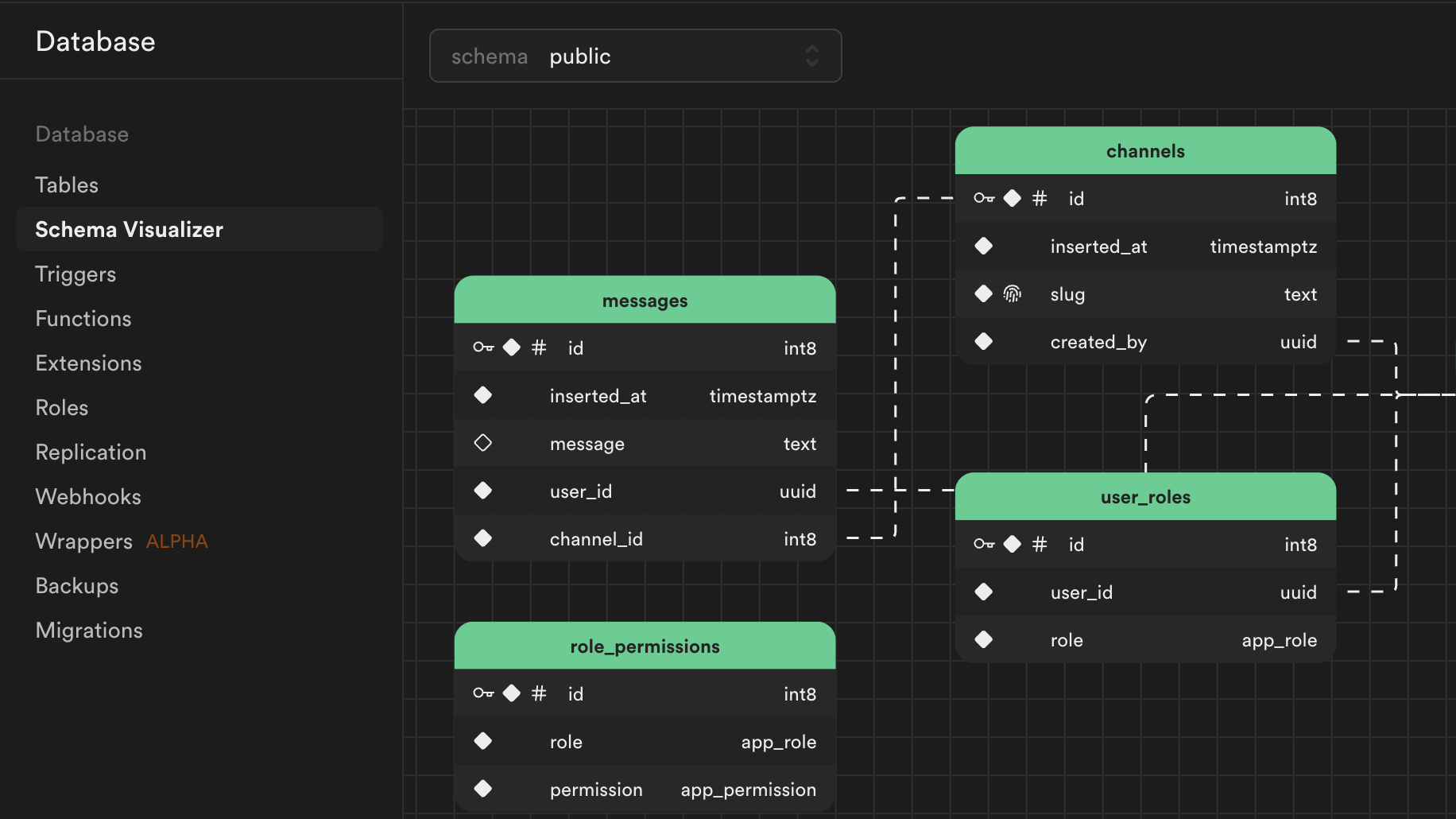
1. Aproveitando o banco de dados PostgreSQL
No coração do Supabase está o PostgreSQL, um dos sistemas de banco de dados relacionais mais populares do mundo. O PostgreSQL é um banco de dados que oferece flexibilidade, escalabilidade e desempenho.
A decisão do Supabase de usar o PostgreSQL como seu banco de dados de backend permite que os desenvolvedores aproveitem todo o poder do SQL enquanto se beneficiam de uma infraestrutura estável e escalável.
Alguns dos principais recursos do banco de dados PostgreSQL gerenciado do Supabase incluem:
- Consultas avançadas: o Supabase oferece suporte a consultas SQL complexas, incluindo junções, agregações e até mesmo pesquisa de texto completo.
- Suporte JSON: o PostgreSQL oferece suporte a tipos de dados JSON, permitindo que você trabalhe com dados estruturados e não estruturados no mesmo banco.
- Segurança em nível de linha: com o Supabase, você pode implementar controle de acesso refinado em nível de linha, garantindo que os usuários possam acessar apenas os dados que estão autorizados a ver.
Além disso, o banco de dados PostgreSQL é totalmente integrado à API do Supabase, o que significa que cada tabela que você cria em seu banco de dados gera automaticamente endpoints RESTful para executar operações CRUD.
Portanto, esse recurso de API instantânea é uma grande economia de tempo para desenvolvedores que, de outra forma, precisariam criar endpoints manualmente para interagir com seus dados.

Exemplo prático: criando uma tabela e acessando via API no Supabase
Imagine que você está construindo um app simples de lista de tarefas (To-Do List).
- No Supabase Dashboard, você cria uma tabela chamada tasks com as seguintes colunas:
- id (inteiro, chave primária)
- title (texto)
- done (booleano, para marcar se a tarefa foi concluída)
- id (inteiro, chave primária)
- Assim que a tabela é criada, o Supabase automaticamente gera endpoints REST para interagir com esses dados.
Para buscar todas as tarefas:
GET https://SEU-PROJETO.supabase.co/rest/v1/tasks
Para adicionar uma nova tarefa:
POST https://SEU-PROJETO.supabase.co/rest/v1/tasks
Content-Type: application/json
{
“title”: “Estudar Supabase”,
“done”: false
}
- O controle de acesso pode ser configurado diretamente no painel, usando Row Level Security (RLS).
- Exemplo: cada usuário só pode visualizar ou editar suas próprias tarefas.
- Exemplo: cada usuário só pode visualizar ou editar suas próprias tarefas.
Isso significa que, em poucos minutos, você já tem um banco de dados relacional completo, com API pronta para uso, autenticação integrada e segurança em nível de linha, sem precisar programar o backend manualmente.
2. Integração de API perfeita com o Supabase
Um dos principais pontos fortes dessa ferramenta é sua abordagem API-first. Os desenvolvedores podem interagir com o backend exclusivamente por meio de uma API RESTful.
Assim, isso facilita a integração do Supabase com diferentes tecnologias de frontend, como React, Vue, Angular e Next.js.
Essa dissociação do frontend do backend permite maior flexibilidade, facilitando a troca ou atualização de estruturas sem precisar revisar todo o backend.
Dessa forma, com a API da Supabase, você pode executar operações CRUD, gerenciar autenticação de usuários e lidar com uploads e downloads de arquivos. Tudo isso sem precisar escrever código complexo do lado do servidor.
A API também é bem documentada, facilitando o início para os desenvolvedores. Assim, seja você um desenvolvedor experiente ou apenas iniciante, a documentação direta e os SDKs tornam o Supabase acessível e rápido de implementar.
Exemplo prático de uso com React
Imagine que você está desenvolvendo um site em React para uma comunidade de cursos online.
Com a API do Supabase, você consegue:
- Gerenciar usuários: cada aluno cria sua conta e faz login usando email ou Google, tudo controlado pela autenticação do Supabase.
- Listar conteúdos do curso: as aulas ficam armazenadas no banco de dados PostgreSQL e são exibidas automaticamente no frontend em React.
- Salvar progresso: quando o aluno marca uma aula como concluída, essa informação é registrada direto na API do Supabase, sem precisar criar um backend separado.
- Armazenar arquivos: PDFs ou materiais de apoio ficam no storage do Supabase e podem ser acessados pelos alunos via links seguros.
Assim, o React cuida da interface e o Supabase entrega o backend completo via API (login, dados e arquivos) sem que você precise programar servidores.
3. Autenticação de usuário facilitada
Implementar a autenticação de usuário é um dos aspectos mais demorados e propensos a erros do desenvolvimento de backend. O Supabase simplifica esse processo ao oferecer um sistema de autenticação abrangente e integrado.
Dessa forma, os desenvolvedores podem implementar registro de usuário seguro, login e gerenciamento de sessão com apenas algumas linhas de código. O Supabase oferece suporte a vários métodos de autenticação, incluindo:
- E-mail/senha: login tradicional com e-mail e senha.
- Logins sociais: autenticação por meio de serviços populares como Google, GitHub e outros.
- Magic Links: login sem senha por e-mail.
Além de lidar com login e registro, o sistema de autenticação do Supabase também oferece suporte a redefinições de senha, verificação de e-mail e gerenciamento de sessão baseado em JWT.

4. Sincronização de dados em tempo real
A funcionalidade em tempo real está se tornando cada vez mais importante em aplicativos modernos. O Supabase se destaca nessa área ao fornecer sincronização de dados em tempo real por meio da replicação PostgreSQL.
Portanto, com o Supabase, você pode facilmente criar aplicativos que reagem a alterações no banco de dados em tempo real.
Por exemplo, se você estiver criando um editor de texto colaborativo, poderá usar o sistema de eventos baseado em WebSocket para garantir que todos os usuários vejam as atualizações.
Esse recurso é possível sem nenhuma configuração ou instalação complexa. Assim, depois que seu banco de dados estiver conectado ao Supabase, você pode começar a ouvir alterações em tempo real usando as bibliotecas de cliente.
5. Armazenamento de arquivos sem complicações
Além de lidar com operações de banco de dados, o Supabase também oferece armazenamento de arquivos. Este recurso é especialmente útil para aplicativos que precisam armazenar e gerenciar conteúdo gerado pelo usuário.
O sistema de armazenamento do Supabase é seguro e vem com políticas de controle de acesso integradas. Você pode criar buckets públicos e privados para gerenciar seus arquivos.
Além disso, a API do Supabase permite que você carregue, baixe e exclua arquivos facilmente de forma programática.
6. Edge Functions do Supabase para execução sem servidor
A ferramenta também oferece suporte a Edge Functions, que são funções leves sem servidor que são executadas na borda, perto de seus usuários.
Essas funções oferecem execução de baixa latência, tornando-as ideais para tarefas que precisam ser executadas de forma rápida e eficiente.
Assim, com as edge functions do Supabase, você pode escrever lógica personalizada do lado do servidor em JavaScript ou TypeScript e implantá-la diretamente no Supabase.
Este recurso é especialmente útil para tarefas como processamento de pagamentos, envio de e-mails transacionais ou transformações de dados.
7. Escalabilidade e segurança
À medida que seu aplicativo cresce, o Supabase escala com você. Como o Supabase é construído sobre o PostgreSQL, ele foi projetado para lidar com grandes volumes de dados e altos níveis de tráfego simultâneo.
A segurança é outra consideração importante para qualquer backend, e essa ferramenta implementa as melhores práticas para criptografia de dados, autenticação e controle de acesso.
Dessa forma, quer você esteja gerenciando dados confidenciais do usuário ou protegendo uploads de arquivos, o Supabase garante que seu aplicativo permaneça seguro e protegido.

Vale a pena usar o Supabase?
O Supabase é uma ferramenta incrivelmente poderosa para desenvolvedores que desejam simplificar o desenvolvimento de backend e ainda ter acesso a uma infraestrutura escalável, segura e rica em recursos.
Ao oferecer um banco de dados PostgreSQL gerenciado, autenticação de usuário, sincronização em tempo real, armazenamento de arquivos e funções de ponta, essa ferramenta fornece uma solução abrangente para a construção de aplicativos modernos.
Portanto, se você está procurando uma alternativa de código aberto ou simplesmente quer simplificar seu desenvolvimento de backend, o Supabase definitivamente vale a pena explorar.
Finalmente, se você quiser saber como tirar o melhor proveito dessa ferramenta, você precisa fazer parte da Formação NoCodeIA! Venha conhecer tudo sobre o mundo NoCode com a gente!
FAQ – Perguntas Frequentes
Para que serve o Supabase?
O Supabase serve para criar o backend de aplicações modernas com banco de dados, autenticação, APIs e armazenamento, tudo pronto sem precisar programar o servidor do zero.
O Supabase é gratuito?
Sim, tem um plano gratuito com limites de uso, ideal para projetos pequenos ou testes.
Qual é melhor, Firebase ou Supabase?
Depende do projeto: o Firebase é ótimo para apps rápidos e NoSQL; o Supabase é melhor para quem quer SQL (PostgreSQL) e mais flexibilidade.