Melhores Backends Nocode: Firebase vs Supabase vs Xano
4 min
Atualizado em 30 de outubro de 2025
Neste artigo, vamos analisar e comparar os melhores backends nocode disponíveis no mercado para auxiliá-lo a escolher a opção mais adequada para o seu projeto.
Levaremos em consideração diversos fatores, como funcionalidades, precificação, comunidade e evolução no mercado.
Após uma extensa pesquisa, selecionamos três backends nocode para analisar em detalhes: Firebase, Supabase e Xano.
Assista um comparativo de Firebase VS Supabase VS Xano
Conteúdo
Frontend VS Backend
Antes de prosseguirmos, é importante entender a diferença entre frontend e backend. O frontend é responsável pela parte visual de um aplicativo, incluindo a lógica, a experiência do usuário (UX/UI). No fluxo moderno o front consome APIs e serviços de auth/storage (a conexão direta ao DB é rara e indesejada).
Já o backend é responsável pelo banco de dados, autenticação, armazenamento de mídias, ações do servidor e webhooks.
Resumindo:
Frontend: tudo que o usuário vê e interage (UI/UX, estado, chamadas HTTP para APIs).
Backend: banco de dados, autenticação/autorização, APIs/funcões (server/edge), armazenamento e integrações (webhooks/filas).
No no-code/low-code, você orquestra esses serviços em plataformas que já entregam API + Auth + Storage prontos como Firebase, Supabase e Xano.
Qual escolher em 10s?
FlutterFlow: Firebase (integrações nativas).
Bubble: Xano (backend visual rápido).
WeWeb: Supabase (relacional e custo/benefício).
Riscos & limites rápidos
Lock-in: Regras, migração de dados.
Limites de planos/free tiers: Leitura/escrita no Firebase; faixas do Supabase; Starter a partir de US$29/m no Xano — novidade 2025.
Firebase
Firebase é o backend mais natural para FlutterFlow, porque o framework já traz widgets e integrações nativas.
O banco de dados é o Firestore (NoSQL orientado a documentos), acompanhado do Realtime Database em casos de sincronização simples.
Quando evitar: se você precisa de joins complexos ou relacional clássico (ex.: ERP, BI), ou se teme lock-in (Firestore não migra fácil).
Quando usar: apps em FlutterFlow, MVPs rápidos, push notifications, auth via Google/Apple, apps mobile-first.
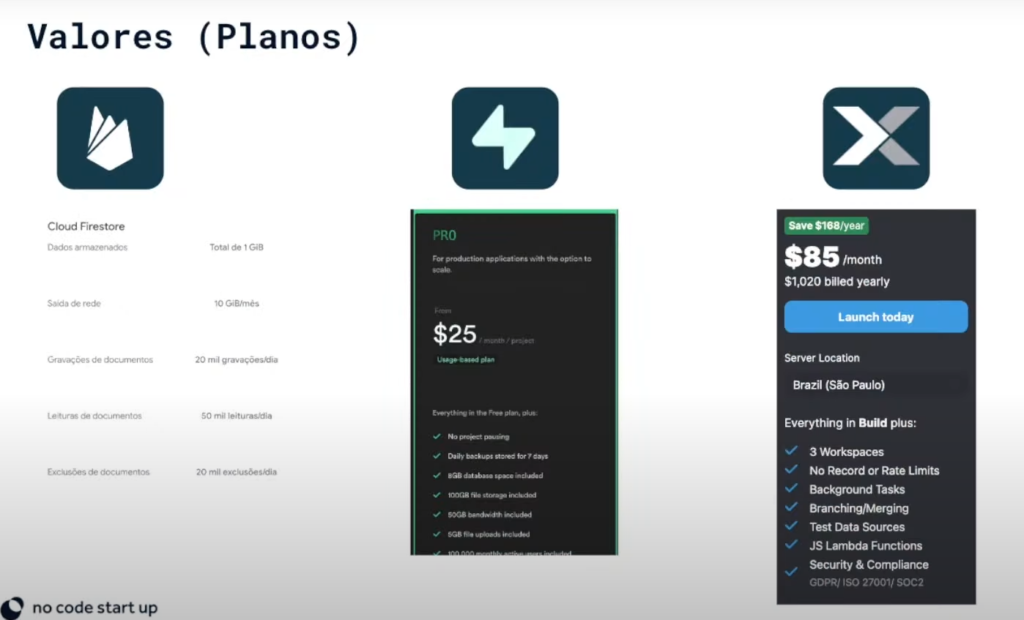
Planos (2025):
Spark (grátis): 50K leituras/dia, 1GB storage.
Blaze (pay as you go): paga por leitura/escrita/GB.
Tip: para apps que crescem rápido, os custos de leitura podem explodir.
Supabase
Supabase é a escolha certa para quem precisa de dados relacionais (Postgres completo). É open-source, com hospedagem gerenciada. Oferece Auth pronto, APIs REST/GraphQL automáticas, Realtime, Edge Functions, Storage CDN e até Vector DB para IA.
Quando usar: SaaS multiusuário, apps que precisam de joins e relatórios, dashboards em WeWeb ou Next.js.
Quando evitar: se você não tem experiência mínima com SQL, ou se precisa de algo 100% visual (Supabase exige lidar com queries).
Xano entrega um backend 100% no-code, focado em criar APIs personalizadas sem precisar de SQL. Traz um editor visual de lógica, ideal para quem não é dev mas precisa de flexibilidade.
Quando usar: projetos no Bubble ou Adalo, MVPs que exigem lógica de negócios complexa (ex.: cálculos, workflows, filtros avançados).
Quando evitar: se você precisa de SQL relacional completo ou quer evitar vendor lock-in (migração difícil).
Planos (2025):
Starter: US$ 29/mês (até 5GB DB e 100K requests).
Growth: US$ 99/mês.
Escala: Enterprise sob demanda.
Tip: comparado ao Firebase, você ganha mais controle sobre lógica e menos surpresas de custo.
Preços dos backends
Os preços das ferramentas variam de acordo com o uso e as funcionalidades escolhidas. O Firebase, por exemplo, cobra de acordo com a leitura e a edição do banco de dados.
Já o Supabase possui um plano gratuito e um plano Pro, com excelente custo-benefício. O Xano tem um custo um pouco mais alto, mas há rumores de que irão oferecer planos regionais com preços mais acessíveis para o Brasil e outras regiões.
Comparativo:
Firebase
Free Tier: 50K leituras/dia + 1GB storage
Plano Pago Inicial: Pay as you go
Modelo de Custo: Por leitura/escrita/storage
Melhor Para: Apps mobile no FlutterFlow
Supabase
Free Tier: 500MB DB + 1GB storage
Plano Pago Inicial: US$25/mês (8GB)
Modelo de Custo: Preço fixo (escalável)
Melhor Para: SaaS, dashboards relacionais
Xano
Free Tier: —
Plano Pago Inicial: US$29/mês (5GB + 100K requests)
Modelo de Custo: Tiers de uso
Melhor Para: MVPs em Bubble/Adalo com lógica complexa
Principais Diferenças entre os Backends Nocode
Cada backend possui seus diferenciais e aplicações ideais. O Firebase é indicado para projetos que exigem flexibilidade no banco de dados não relacional e integrações com os serviços do Google.
O Supabase é recomendado para projetos com banco de dados relacional e que demandam facilidade de uso e custo-benefício.
Por fim, o Xano é ideal para projetos 100% no code, oferecendo flexibilidade, facilidade de aprendizado e independência.
Matriz de decisão (casos de uso):
App mobile em FlutterFlow: Firebase (SDK e integração nativa)
SaaS multiusuário (WeWeb, Next.js): Supabase (Relacional + API pronta)
MVP em Bubble/Adalo: Xano (Backend visual rápido)
Projeto que exige joins complexos: Supabase (SQL completo)
Projeto que exige lógica custom sem SQL: Xano (Editor de lógica visual)
Protótipo rápido e barato: Firebase (Free tier robusto)
Qual backend no-code escolher?
Não existe “o melhor” universal.
Se você está no FlutterFlow, comece pelo Firebase.
Se precisa de SQL relacional e previsibilidade de preço, vá de Supabase.
Se quer construir lógica visual sem código em Bubble/Adalo, Xano é seu aliado.
O mais importante é testar rapidamente com seu front-end e validar o custo no seu cenário.
Neto se especializou em Bubble pela necessidade de criar tecnologias de forma rápida e barata para sua startup, desde então vem criando sistemas e automações com IA.
No Bubble Developer Summit 2023 foi elencado como um dos maiores mentores de Bubble do mundo.
Em Dezembro foi nomeado maior membro da comunidade global de NoCode no NoCode Awards 2023 e primeiro lugar do concurso de melhor aplicativo organizado pela própria Bubble.
Hoje Neto tem como foco em criar soluções de Agentes IA e automações usando N8N e Open AI.
Papo reto: 2026 vai ser um divisor de águas para quem quer ganhar dinheiro com IA (Inteligência Artificial). As oportunidades existem, mas nem todas valem o seu tempo, e algumas prometem muito mais do que entregam.
Neste artigo, eu organizei as principais formas de monetizar IA em categorias claras, com prós, contras e o nível real de esforço envolvido. A ideia aqui é te ajudar a escolher um caminho consciente, sem cair em atalhos ilusórios.
Conteúdo
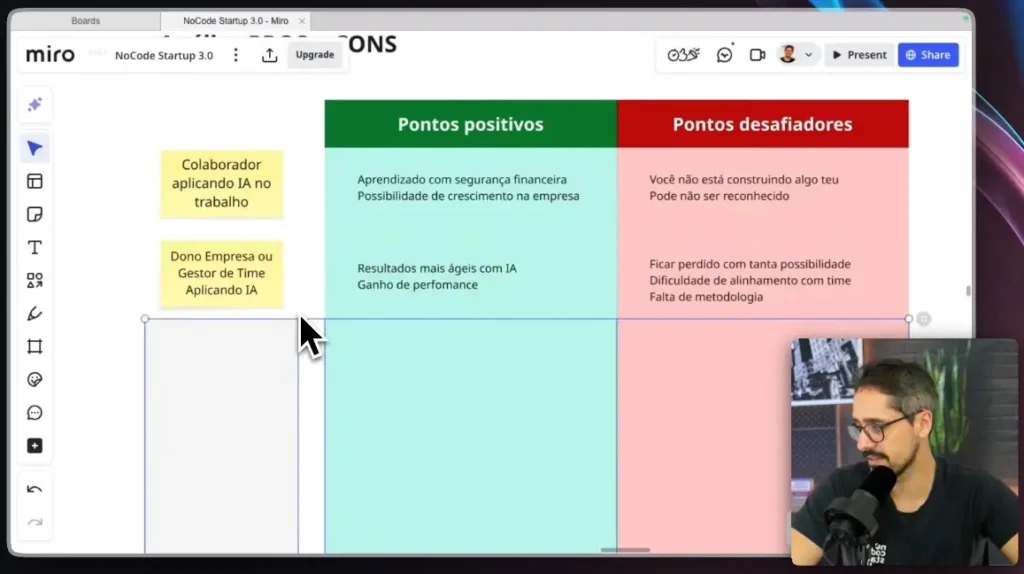
IA aplicada no trabalho como colaborador (carreira e segurança)
Se você já trabalha em uma empresa, aplicar IA no seu dia a dia é uma das formas mais seguras de começar. Você aprende, experimenta e constrói projetos reais sem abrir mão da estabilidade financeira.
É possível criar automações, agentes e até softwares internos que aumentam eficiência, reduzem custos e geram impacto direto no negócio. Quando isso acontece, o reconhecimento tende a vir — desde que você gere resultado real, e não apenas “use IA por usar”.
O ponto de atenção é entender que você não está construindo algo seu. Mesmo assim, para aprendizado e crescimento profissional, essa é uma das melhores portas de entrada.
IA para gestores e donos de empresas
Para gestores e donos de empresa, a IA representa talvez a maior oportunidade financeira de 2026. A maioria das empresas ainda está perdida, sem método, sem estratégia e sem clareza de como aplicar IA nos processos.
Quando bem aplicada, a IA melhora performance, reduz gargalos e acelera resultados em vendas, atendimento e operação. O desafio está no excesso de ferramentas e na falta de metodologia clara para o time.
Quem conseguir organizar esse caos e aplicar IA com foco em resultado vai capturar muito valor. Aqui, realmente, existe muito dinheiro na mesa.
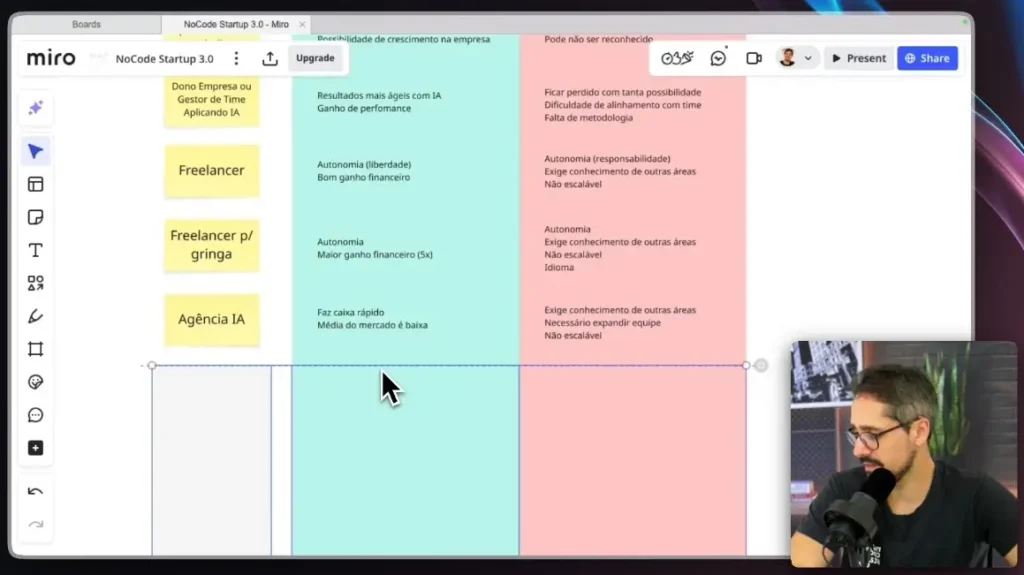
Prestação de serviços com IA: visão geral
A prestação de serviços com IA é um dos caminhos mais rápidos para gerar renda. Você resolve problemas reais de empresas usando automações, agentes e sistemas inteligentes.
Esse modelo se desdobra em freelancer, freelancer para a gringa, agência e consultoria. Cada um tem um nível diferente de esforço, retorno e complexidade, mas todos exigem execução.
É aqui que muita gente começa a “fazer a roda girar” de verdade.
Freelancer para a gringa (ganhar em dólar)
Ser freelancer para a gringa é, sem exagero, uma das melhores opções para ganhar dinheiro com IA. Os ganhos em dólar ou euro mudam completamente o jogo.
Você continua trocando tempo por dinheiro, mas com um retorno muito maior. O maior desafio é o começo: conseguir o primeiro projeto e lidar com o idioma, mesmo que em nível básico.
Depois que o primeiro cliente vem, indicações começam a aparecer. Para quem quer resultado rápido e tem disposição para vender o próprio serviço, esse caminho é forte demais.
Criando uma agência de IA
A agência de IA é a evolução natural do freelancer. Aqui, você escala pessoas, projetos e faturamento.
O mercado ainda é imaturo, muita gente faz tudo errado, e isso abre espaço para quem faz o básico bem feito. Você consegue fechar contratos, montar equipe e entregar soluções completas com IA.
O desafio passa a ser gestão: pessoas, prazos, processos e qualidade. Mesmo assim, para 2026, é uma das formas mais rápidas de monetizar IA com consistência.
👉 Entre para a Formação IA Coding e aprenda a criar prompts completos, automações e aplicativos com IA — saindo do zero até projetos reais em poucos dias.
Consultoria em IA para empresas
Consultoria é um modelo extremamente lucrativo, mas não é ponto de partida. Ela exige experiência prática, visão de processos e capacidade de diagnóstico.
O retorno financeiro costuma ser alto em relação ao tempo investido. Por outro lado, você precisa ter autoridade, histórico e repertório real de projetos.
Para quem já passou por agência, produtos ou grandes implementações, é um caminho excelente. Para iniciantes, ainda não faz sentido.
Founder: criar aplicativos com IA
Criar aplicativos com IA nunca foi tão acessível. Ferramentas como Lovable, Cursor e integrações com Supabase tornam isso possível mesmo sem background técnico.
O potencial financeiro é alto, mas a dificuldade também. Criar tecnologia deixou de ser o diferencial — hoje, o desafio está em marketing, distribuição, financeiro e validação.
É um caminho de muito aprendizado, mas com alta taxa de erro no início. Vale a pena se você estiver disposto a errar, aprender e iterar.
Micro SaaS com IA (prós e contras)
O Micro SaaS resolve um problema específico de um nicho específico. Isso reduz concorrência e aumenta clareza de proposta.
Ele não escala como um SaaS tradicional, mas pode gerar uma renda consistente e sustentável. O desafio continua sendo o mesmo: marketing, vendas e gestão.
Não é fácil, não é rápido, mas pode ser um ótimo negócio paralelo. Aqui, eu classifico como um caminho “ok”, desde que você tenha paciência.
SaaS tradicional com IA
O SaaS tradicional tem maior potencial de escala, mas também maior concorrência. Você resolve problemas mais amplos e disputa mercados maiores.
Isso exige mais tempo, mais capital emocional e mais capacidade de execução. Por isso, muitas vezes, o Micro SaaS acaba sendo uma escolha mais inteligente no começo.
SaaS é poderoso, mas definitivamente não é o caminho mais simples.
Educação com IA: cursos e infoprodutos
Educação com IA é extremamente escalável. Depois que o produto está pronto, a entrega é quase automática.
O problema é o tempo. Criar audiência, produzir conteúdo e construir autoridade leva meses — às vezes anos.
Aqui na NoCode Startup, demoramos bastante até o projeto se tornar realmente relevante financeiramente. Funciona, mas exige consistência e visão de longo prazo.
Comunidades de IA
Comunidades geram networking, recorrência e autoridade. Mas também exigem presença constante, eventos, suporte e muita energia.
É um modelo poderoso, porém trabalhoso. Não recomendo como primeiro passo para quem está começando agora.
Com experiência e audiência, pode se tornar um ativo incrível.
Templates, e-books e produtos simples com IA
Templates e e-books são fáceis de criar e escalar. Justamente por isso, a concorrência é enorme e o valor percebido costuma ser baixo.
Hoje, se algo pode ser resolvido com uma pergunta no ChatGPT, fica difícil vender apenas informação. Esses produtos funcionam melhor como complemento, não como negócio principal.
Para ganhar dinheiro de verdade com IA, entregar execução e resultado é o que faz a diferença.
Próximo passo
Não existe dinheiro fácil com IA. O que existe é mais acesso, mais ferramentas e mais possibilidades para quem executa bem.
Os caminhos mais sólidos passam por prestação de serviços, produtos bem posicionados e construção de autoridade. Quanto mais fácil algo parece, maior tende a ser a concorrência.
Se você quer aprender IA de forma prática, estruturada e com foco em projetos reais, conheça a Formação IA Coding.
A tecnologia vive uma transição histórica: de softwares passivos para sistemas autônomos. Entender os tipos de agentes de IA é descobrir ferramentas capazes de perceber, raciocinar e agir sozinhas para cumprir metas complexas, sem a necessidade de microgerenciamento.
Essa evolução transformou o mercado. Para profissionais que desejam liderar a infraestrutura de IA, dominar a taxonomia desses agentes não é mais opcional.
É o diferencial competitivo exato entre lançar um chatbot básico ou orquestrar uma força de trabalho digital completa.
Neste guia definitivo, vamos dissecar a anatomia dos agentes, explorando desde as classificações clássicas até as modernas arquiteturas baseadas em LLMs que estão revolucionando o mundo No-Code e High-Code.
Diagrama ilustrando o loop de percepção, raciocínio e ação de diferentes tipos de agentes de IA em um ambiente digital
O Que Define Exatamente um Agente de IA?
Antes de explorarmos os tipos, é fundamental traçar uma linha clara na areia. Um agente de inteligência artificial não é meramente um modelo de linguagem ou um algoritmo de Machine Learning.
A definição mais rigorosa, aceita tanto na academia quanto na indústria, como no curso CS221 da Stanford, descreve um agente como uma entidade computacional situada em um ambiente, capaz de percebê-lo através de sensores e agir sobre ele através de atuadores para maximizar suas chances de sucesso.
A Diferença Crucial: Modelo de IA vs. Agente de IA
Muitos iniciantes confundem o motor com o carro.
Modelo de IA (ex: GPT-4, Llama 3): É o cérebro passivo. Se você não enviar um prompt, ele não faz nada. Ele possui conhecimento, mas não tem agência.
Agente de IA: É o sistema completo. Ele possui o modelo como núcleo de raciocínio, mas também tem memória, acesso a ferramentas (banco de dados, APIs, navegadores) e, crucialmente, um objetivo.
Um agente utiliza as previsões do modelo para tomar decisões sequenciais, gerenciar estados e corrigir o curso de suas ações.
É a diferença entre perguntar ao ChatGPT “como enviar um e-mail” (Modelo) e ter um software que escreve, agenda e envia o e-mail para sua lista de contatos autonomamente (Agente).
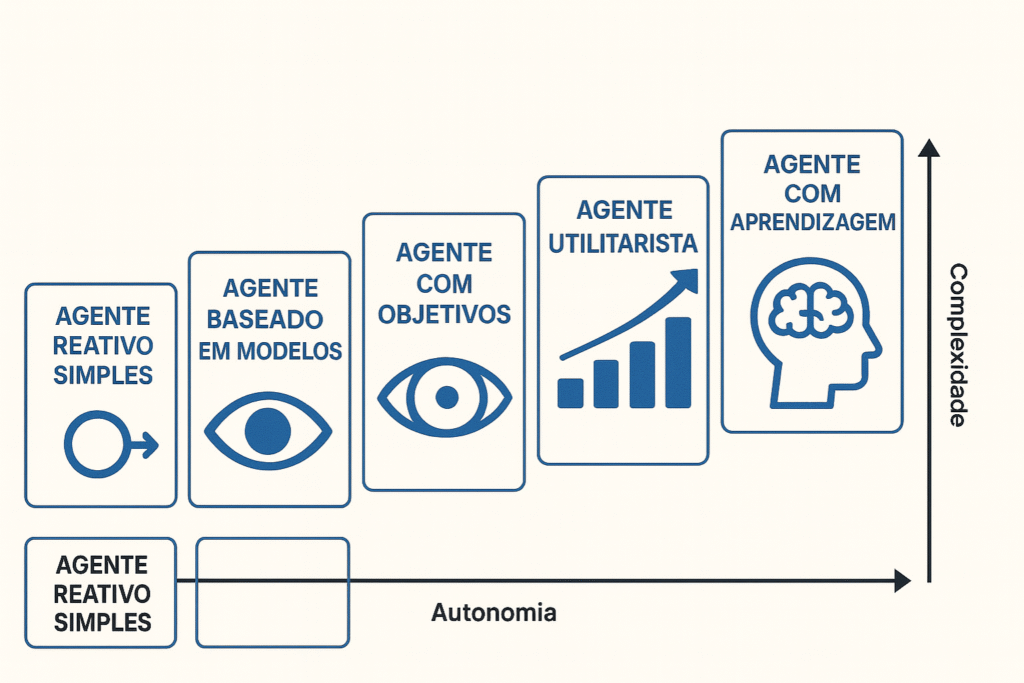
Os 5 Tipos Clássicos de Agentes de IA
Para construir soluções robustas, precisamos revisitar a base teórica estabelecida por Stuart Russell e Peter Norvig, os pais da IA moderna.
A complexidade de um agente é determinada pela sua capacidade de lidar com incertezas e manter estados internos.
Aqui estão os 5 tipos de agentes de IA hierárquicos que formam a base de qualquer automação inteligente:
1. Agentes Reativos Simples
Este é o nível mais básico de inteligência. Os agentes reativos simples operam no princípio de “condição-ação” (IF-THEN).
Eles respondem apenas ao input atual, ignorando completamente o histórico ou estados passados.
Como funciona: Se o sensor detecta “X”, o atuador faz “Y”.
Exemplo: Um termostato inteligente ou um filtro de spam básico. Se a temperatura passa de 25ºC, liga o ar condicionado.
Limitação: Eles falham em ambientes complexos onde a decisão depende de um contexto histórico.
2. Agentes Reativos Baseados em Modelos
Dando um passo além, estes agentes mantêm um estado interno — uma espécie de memória de curto prazo.
Eles não olham apenas para o “agora”, mas consideram como o mundo evolui independentemente de suas ações.
Isso é vital para tarefas onde o ambiente não é totalmente observável. Por exemplo, em um carro autônomo, o agente precisa lembrar que havia um pedestre na calçada há 2 segundos, mesmo que um caminhão tenha bloqueado sua visão momentaneamente.
3. Agentes Baseados em Objetivos
A inteligência real começa aqui. Os agentes baseados em objetivos não apenas reagem; eles planejam.
Eles possuem uma descrição clara de um estado “desejável” (o objetivo) e avaliam diferentes sequências de ações para alcançá-lo.
Isso introduz a capacidade de busca e planejamento. Se o objetivo é “otimizar o banco de dados”, o agente pode simular vários caminhos antes de executar o comando final, algo essencial para quem trabalha com IA para análise de dados.
4. Agentes Baseados em Utilidade
Muitas vezes, atingir o objetivo não é suficiente; é preciso atingi-lo da melhor maneira possível. Os agentes baseados em utilidade utilizam uma função de utilidade (pontuação) para medir a preferência entre diferentes estados.
Se um agente de logística tem o objetivo de entregar um pacote, o agente de utilidade vai calcular não apenas a rota que chega lá, mas a que chega mais rápido, gastando menos combustível e com maior segurança. É a maximização da eficiência.
5. Agentes com Aprendizagem
No topo da hierarquia clássica estão os agentes capazes de evoluir. Eles possuem um componente de aprendizagem que analisa o feedback de suas ações passadas para melhorar seu desempenho futuro.
Eles começam com conhecimento básico e, através da exploração do ambiente, ajustam suas próprias regras de decisão. É o princípio por trás de sistemas de recomendação avançados e robótica adaptativa.
Infográfico comparando a complexidade e autonomia dos cinco tipos de agentes de IA clássicos, do reativo simples ao agente com aprendizagem
O que são agentes generativos baseados em LLMs?
A taxonomia clássica evoluiu. Com a chegada dos Grandes Modelos de Linguagem (LLMs), surgiu uma nova categoria que domina as discussões atuais: os Agentes Generativos.
Nestes sistemas, o LLM atua como o controlador central ou “cérebro”, utilizando sua vasta base de conhecimento para raciocinar sobre problemas que não foram explicitamente programados, conforme detalhado no paper seminal sobre Generative Agents.
Frameworks de Raciocínio: ReAct e CoT
Para que um LLM funcione como um agente eficaz, utilizamos técnicas de prompt engineering avançadas que estruturam o pensamento do modelo:
Chain-of-Thought (CoT): O agente é instruído a quebrar problemas complexos em passos intermediários de raciocínio lógico (“Vamos pensar passo a passo”). Pesquisas indicam que essa técnica estimula o raciocínio complexo em grandes modelos.
ReAct (Reason + Act): Esta é a arquitetura mais popular atualmente. O agente gera um pensamento (Reason), executa uma ação em uma ferramenta externa (Act) e observa o resultado (Observation). Esse loop, descrito no paper ReAct: Synergizing Reasoning and Acting, permite que ele interaja com APIs, leia documentações ou execute código Python em tempo real.
Ferramentas como o AutoGPT e BabyAGI popularizaram o conceito de agentes autônomos que criam suas próprias listas de tarefas baseadas nesses frameworks.
Dica de Especialista: Para quem deseja aprofundar na criação técnica destes sistemas, nossa Formação AI Coding explora exatamente como orquestrar esses frameworks para criar softwares inteligentes.
Arquiteturas: Agente Único vs. Sistemas Multiagente
Ao desenvolver uma solução para sua empresa, você enfrentará uma escolha arquitetural crítica: devo usar um super agente que faz tudo ou vários especialistas?
Qual a diferença entre Agente Único e Sistemas MultiAgentes?
A diferença está na forma de organização da inteligência. Um Agente Único concentra toda a lógica e execução em uma única entidade, sendo mais simples, rápido e fácil de manter, ideal para tarefas diretas e de escopo bem definido.
Já os Sistemas MultiAgentes distribuem o trabalho entre agentes especializados, cada um responsável por uma função específica.
Essa abordagem aumenta a capacidade de resolver problemas complexos, melhora a qualidade dos resultados e facilita a escalabilidade da solução.
Quando usar um Agente Único?
Um agente único é ideal para tarefas lineares e de escopo fechado. Se o objetivo é “resumir este PDF e enviar por e-mail”, um único agente com as ferramentas certas é eficiente e fácil de manter.
A latência é menor e a complexidade de desenvolvimento é reduzida.
O Poder da Orquestração Multiagente
Para problemas complexos, a indústria está migrando para Sistemas Multiagente (MAS). Imagine uma agência digital: você não quer que o redator faça o design e aprove o orçamento.
Um agente “Crítico” que revisa o trabalho antes da entrega.
Essa especialização imita estruturas organizacionais humanas e tende a produzir resultados de qualidade superior.
Frameworks modernos facilitam essa orquestração, como o LangGraph para controle de fluxo complexo, o CrewAI para times de agentes baseados em papéis, e até mesmo bibliotecas mais leves como smolagents da Hugging Face.
Representação visual de um sistema multi agente onde agentes especializados colaboram para resolver um problema complexo de negócios
Aplicações Práticas e Ferramentas No-Code
A teoria é fascinante, mas como isso se traduz em valor real? Os diferentes tipos de agentes de IA já estão operando nos bastidores de grandes operações e startups ágeis.
Agentes de Coding e Desenvolvimento
Agentes autônomos como o Devin ou implementações open-source como o OpenDevin utilizam arquiteturas de planejamento e uso de ferramentas para escrever, depurar e implantar código inteiro.
No cenário No-Code, ferramentas como FlutterFlow e Bubble estão integrando agentes que auxiliam na construção de interfaces e lógicas complexas apenas com comandos de texto.
Agentes de Análise de Dados
Em vez de depender de analistas para gerar relatórios SQL manuais, agentes baseados em utilidade e objetivos podem conectar-se ao seu Data Warehouse, formular queries, analisar tendências e gerar insights proativos.
Agentes de atendimento ao cliente (Customer Experience) que não apenas respondem dúvidas, mas acessam o CRM para processar reembolsos ou alterar planos, são exemplos de agentes baseados em objetivos que geram ROI imediato.
Empresas como a Zapier e a Salesforce já oferecem plataformas dedicadas para criar esses assistentes corporativos.
Interface de um dashboard empresarial mostrando métricas de desempenho otimizadas por agentes de IA autônomos
Perguntas Frequentes sobre Agentes de IA
Aqui estão as dúvidas mais comuns que recebemos da comunidade e que dominam as buscas no Google e em fóruns como o Reddit:
Qual é a diferença entre um Chatbot e um Agente de IA?
Um chatbot tradicional geralmente segue um script rígido ou apenas responde com base em texto treinado.
Um Agente de IA tem autonomia: ele pode usar ferramentas (como calculadora, agenda, e-mail) para executar tarefas reais no mundo, não apenas conversar.
O que são agentes autônomos?
São sistemas que podem operar sem intervenção humana constante. Você define um objetivo amplo (ex: “Descubra as 5 melhores ferramentas de SEO e crie uma tabela comparativa”), e o agente autônomo decide quais sites visitar, quais dados extrair e como formatar o resultado sozinho.
Preciso saber programar para criar um Agente de IA?
Não necessariamente. Embora o conhecimento de lógica seja vital, plataformas modernas e frameworks No-Code permitem a criação de agentes poderosos através de interfaces visuais e linguagem natural.
Para customizações avançadas, no entanto, entender a lógica de AI Coding é um diferencial enorme.
Conceito futurista de colaboração humano IA, onde desenvolvedores orquestram múltiplos tipos de agentes de IA em um ambiente de trabalho digital
O Futuro é Agêntico — E Exige Arquitetos, Não Apenas Usuários
Compreender os tipos de agentes de IA é o primeiro passo para sair da posição de consumidor de tecnologia para a de criador de soluções.
Seja um agente reativo simples para triagem de e-mails ou um complexo sistema multi-agente para gerir operações de e-commerce, a autonomia digital é a nova fronteira da produtividade.
O mercado não busca mais apenas quem sabe usar o ChatGPT, mas quem sabe arquitetar os fluxos de trabalho que o ChatGPT (e outros modelos) irão executar.
Se você quer sair da teoria e dominar a construção dessas ferramentas, o próximo passo ideal é conhecer a nossa Formação Gestor de Agentes de IA. A era dos agentes apenas começou — e você pode estar no comando dela.
Se você está buscando criar projetos mais avançados, com melhor segurança, mais escalabilidade e mais profissionais usando as ferramentas do Vibe Coding, este guia é para você.
Neste artigo, separei três dicas bem importantes que vão te guiar do nível iniciante para projetos avançados e verdadeiramente profissionais.
É preciso ir além da simples interface visual e construir uma arquitetura sólida. Vamos lá!
Conteúdo
Por que unir Lovable, N8N e Supabase?
Dica 1: Começando e focando na dor principal
Minha primeira dica é que você comece com o Lovable, mas focando em projetos mais simples, direto ao ponto, na dor que você quer resolver com a tecnologia.
Seja um SaaS, um Micro SaaS ou um aplicativo, descubra qual é a principal dor do seu usuário final.
É fundamental não cair no erro de colocar “um milhão de funcionalidades, um milhão de métricas” e regras de negócio complexas logo no início. Isso confunde o usuário e, com certeza, fará o projeto dar errado.
Foque em criar no Lovable — ele cria apps muito bonitos e visuais. Resolva a dor principal e só depois você vai deixando o projeto mais complexo.
Case
Um exemplo bem interessante, e um dos principais cases do Lovable, é a Plink.
Basicamente, é uma plataforma onde as mulheres conseguem procurar se o seu namorado já teve alguma passagem pela polícia ou tem algum histórico de agressividade.
A criadora, Sabrina, ficou famosa porque criou o app sem saber nada de código, focou na dor principal e o aplicativo simplesmente “explodiu”.
Em apenas dois meses, o projeto já projetava 2.2 milhões de receita. Ela validou a ideia no Lovable, provando que o foco no mercado é o que faz o projeto dar certo.
Outro exemplo é um aplicativo de gestão de agentes de IA. A gente sempre começa no Lovable pela interface e só depois migra o projeto para o Cursor para deixá-lo mais avançado e complexo.
Domine o Supabase, o coração dos projetos avançados
A segunda dica, e a mais importante para a segurança e a escalabilidade, é você aprender bem a parte do Supabase. Ele engloba a modelagem de dados e todas as funções de Back-end.
Para criar projetos de IA, você terá o Front-end (a interface que o usuário vê, como no Lovable) e o Back-end (a inteligência, dados, segurança e escalabilidade).
O Back-end utiliza o N8N para automações e agentes de IA, mas é o Supabase que será o coração do seu projeto.
Se você quer um projeto muito seguro e escalável, o segredo é dominar o Supabase.
A grande vantagem é que, se a interface criada pelo Lovable der problema, como você já tem o coração do seu projeto bem estruturado, você consegue simplesmente remover o Lovable e plugar os dados em outra interface, como o Cursor.
Você não precisa ser técnico, mas precisa entender o Macro: como funciona a modelagem de dados, a segurança (RLS) e a conexão dos dados.
Entender esse básico é crucial para você conseguir pedir e gerenciar a IA de forma eficaz. Para isso, recomendo nosso curso Curso Supabase na assinatura PRO.
Dica 3: Quando avançar para Cursor/ editores de código com IA
A terceira dica é sobre dar o próximo passo: migrar para ferramentas e editores de código com IA, como o Cursor ou o Cloud Code.
É muito importante começar no Lovable de forma simplificada, mas se você quiser deixar seu projeto mais avançado, robusto e escalável, precisará unir a organização do seu Back-end no Supabase com o maior controle oferecido por essas ferramentas.
Porém, é fundamental entender que saber bem o Supabase é um pré-requisito antes de pular para o Cursor, pois você precisa ter o banco de dados e a arquitetura muito bem organizados.
Para projetos complexos, essa união é a chave para ter controle total do código e da estrutura.
Conheça a Formação AI Coding: Domine a criação de prompts, crie agentes avançados e lance aplicativos completos em tempo recorde.