Nos últimos cinco anos, o Hugging Face evoluiu de um chatbot lançado em 2016 para um hub colaborativo que reúne modelos pré‑treinados, bibliotecas e apps de IA; é a forma mais rápida e econômica de validar soluções de NLP e levá‑las ao mercado.
Graças à comunidade vibrante, à documentação detalhada e à integração nativa com PyTorch, TensorFlow and JAX, o Hugging Face tornou‑se a plataforma de referência para adotar IA com rapidez; neste guia, você vai entender o que é, como usar, quanto custa e qual o caminho mais curto para colocar modelos pré‑treinados em produção sem complicação.
Dica Pro: Se o seu objetivo é dominar IA sem depender totalmente de código, confira a nossa AI Agent and Automation Manager Training – nela mostramos como conectar modelos do Hugging Face a ferramentas no‑code como Make, Bubble e FlutterFlow.

O que é o Hugging Face – e por que todo projeto moderno de NLP passa por ele?
Em essência, o Hugging Face é um repositório colaborativo open‑source onde pesquisadores e empresas publicam modelos pré‑treinados para tarefas de linguagem, visão e, mais recentemente, multimodalidade. Porém, limitar‑se a essa definição seria injusto, pois a plataforma agrega três componentes-chave:
- Hugging Face Hub – um “GitHub para IA” que versiona modelos, datasets and apps interativos, chamados de Spaces.
- Biblioteca Transformers – a API Python que expõe milhares de modelos state‑of‑the‑art com apenas algumas linhas de código, compatível com PyTorch, TensorFlow e JAX.
- Ferramentas auxiliares – como datasets (ingestão de dados), diffusers (modelos de difusão para geração de imagens) e evaluate (métricas padronizadas).
Dessa forma, desenvolvedores podem explorar o repositório, baixar pesos treinados, ajustar hyperparameters em notebooks e publicar demos interativas sem sair do ecossistema.
Consequentemente, o ciclo de desenvolvimento e feedback fica muito mais curto, algo fundamental em cenários de prototipagem de MVP – uma dor comum aos nossos leitores da persona Founder.

Principais produtos e bibliotecas (Transformers, Diffusers & cia.)
A seguir mergulhamos nos pilares que dão vida ao Hugging Face. Repare como cada componente foi pensado para cobrir uma etapa específica da jornada de IA.
Transformers
Criada inicialmente por Thomas Wolf, a biblioteca transformers abstrai o uso de arquiteturas como BERT, RoBERTa, GPT‑2, T5, BLOOM e Llama.
O pacote traz tokenizers eficientes, classes de modelos, cabeçalhos para tarefas supervisionadas e até pipelines prontos (pipeline(“text-classification”)).
Com isso, tarefas complexas viram funções de quatro ou cinco linhas, acelerando o time‑to‑market.
Datasets
Com datasets, carregar 100 GB de texto ou áudio passa a ser trivial. A biblioteca streama arquivos em chunks, faz caching inteligente e permite transformações (map, filter) em paralelo. Para quem quer treinar modelos autorregressivos ou avaliá‑los com rapidez, essa é a escolha natural.
Diffusers
A revolução da IA generativa não se resume ao texto. Com diffusers, qualquer desenvolvedor pode experimentar Stable Diffusion, ControlNet e outros modelos de difusão. A API é consistente com transformers, e o time do Hugging Face mantém atualizações semanais.
Gradio & Spaces
O Gradio virou sinônimo de demos rápidas. Criou um Interface, passou o modelo, deu deploy – pronto, nasceu um Space público.
Para startups é uma chance de mostrar provas de conceito a investidores sem gastar horas configurando front-end.
Se você deseja aprender como criar MVPs visuais que consomem APIs do Hugging Face, veja nosso FlutterFlow Course e integre IA em apps móveis sem escrever Swift ou Kotlin.
Hugging Face é pago? Esclarecendo mitos sobre custos
Muitos iniciantes perguntam se “o Hugging Face é pago”. A resposta curta: há um plano gratuito robusto, mas também modelos de assinatura para necessidades corporativas.
Gratuito: inclui pull/push ilimitado de repositórios públicos, criação de até três Spaces gratuitos (60 min de CPU/dia) e uso irrestrito da biblioteca transformers.
Pro & Enterprise: adicionam repositórios privados, quotas maiores de GPU, auto‑scaling para inferência e suporte dedicado.
Empresas reguladas, como as do setor financeiro, ainda podem contratar um deployment on‑prem para manter dados sensíveis dentro da rede.
Portanto, quem está validando ideias ou estudando individualmente dificilmente precisará gastar.
Só quando o tráfego de inferência cresce é que faz sentido migrar para um plano pago – algo que normalmente coincide com tração de mercado.
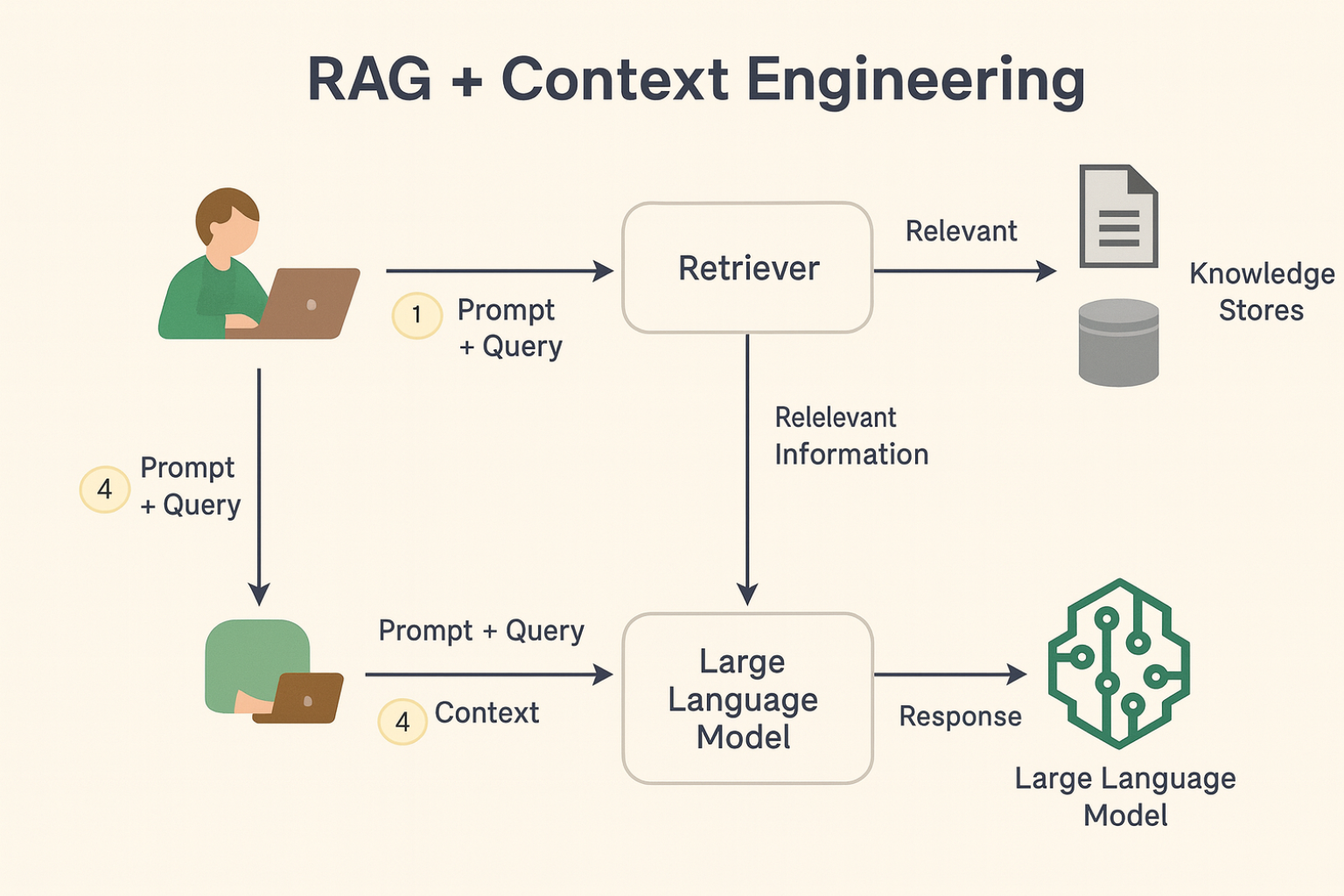
Como começar a usar o Hugging Face na prática
Seguir tutoriais picados costuma gerar frustração. Por isso, preparamos um roteiro único que cobre do primeiro pip install até o deploy de um Space. É a única lista que usaremos neste artigo, organizada em ordem lógica:
- Create an account em https://huggingface.co e configure seu token de acesso (Settings ▸ Access Tokens).
- Instale bibliotecas‑chave: pip install transformers datasets gradio.
- Faça o pull de um modelo – por exemplo, bert-base-uncased – com from transformers import pipeline.
- Rode inferência local: pipe = pipeline(“sentiment-analysis”); pipe(“I love No Code Start Up!”). Observe a resposta em milissegundos.
- Publique um Space com Gradio: crie app.py, declare a interface e push via huggingface-cli. Em minutos você terá um link público para compartilhar.
Depois de executar esses passos, você já poderá:
• Ajustar modelos com fine‑tuning
• Integrar a API REST à sua aplicação Bubble
• Proteger inferência via chaves de API privadas
Integração com Ferramentas NoCode e Agentes de IA
Um dos diferenciais do Hugging Face é a facilidade de plugá‑lo em ferramentas sem código. Por exemplo, no N8N você pode receber textos via Webhook, enviá-los à pipeline de classificação e devolver tags analisadas em planilhas Google – tudo sem escrever servidores.
Já no Bubble, a API Plugin Connector importa o endpoint do modelo e expõe a inferência num workflow drag‑and‑drop.
Se quiser aprofundar esses fluxos, recomendamos o nosso Make Course (Integromat) and the SaaS IA NoCode Training, onde criamos projetos de ponta a ponta, incluindo autenticação, armazenamento de dados sensíveis e métricas de uso.