Building scalable and secure applications today requires a robust backend infrastructure. However, for many developers, managing the complexities of servers, authentication systems, and storage can be a daunting task. This is where Supabase comes into play.
Supabase is a Backend as a Service (BaaS) platform that offers authentication, a PostgreSQL database, automated APIs, and ready-to-use edge functions.
It is considered by many to be the open-source alternative to Firebase, but with advanced features for those who need to scale projects professionally.
In this guide, we'll explore everything you need to know about Supabase, its key features, and how it can help developers streamline their workflow.
What is Supabase?
Supabase is a powerful, open-source alternative to Firebase, offering a database PostgreSQL managed.
In order to combine real-time features, user authentication, file storage, and even serverless functions.
The platform was designed with the goal of simplifying backend development while providing scalability and security.
Unlike traditional backends, Supabase handles much of the heavy lifting, offering a managed backend with minimal configuration.
Developers can focus on building their frontend applications while leveraging Supabase's backend capabilities through an API.

Why choose Supabase?
Supabase’s main appeal lies in its ability to provide developers with a robust backend that doesn’t require complex configuration or management. Traditionally, developers would have to deal with multiple configurations separately.
Supabase brings all of these features together into one cohesive package, reducing the need to juggle multiple services and tools. Another significant benefit is its open source nature.
While Firebase is a closed ecosystem with proprietary technology, Supabase is built with the best tools open source, primarily PostgreSQL.
This means you get the flexibility and transparency of open-source software without sacrificing the benefits of a managed service.
Now, let’s dive deeper into the key features of Supabase.
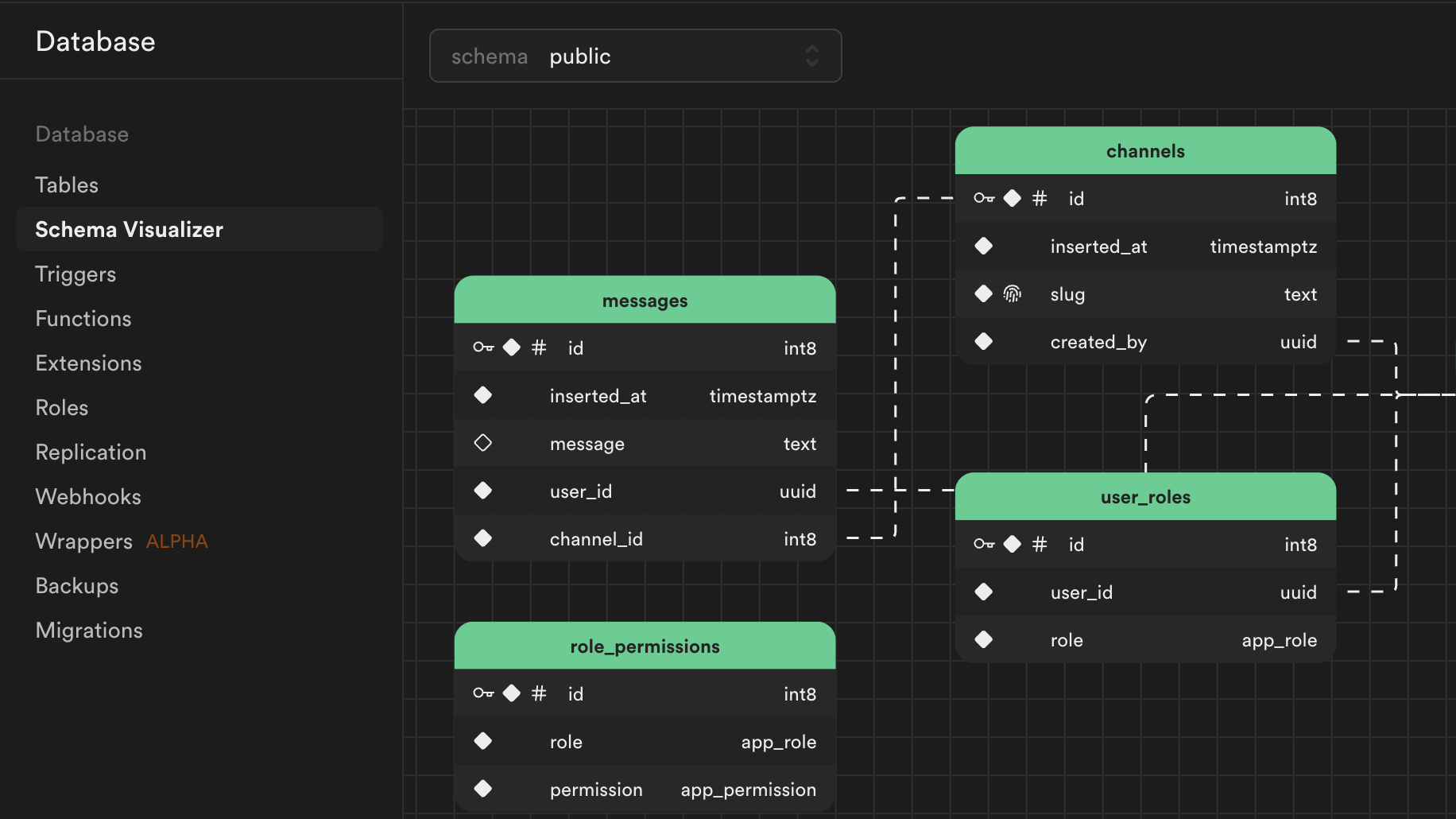
1. Leveraging the PostgreSQL database
At the heart of Supabase is PostgreSQL, one of the world's most popular relational database systems. PostgreSQL is a database that offers flexibility, scalability, and performance.
Supabase's decision to use PostgreSQL as its backend database allows developers to leverage the full power of SQL while benefiting from a stable and scalable infrastructure.
Some of the key features of Supabase's managed PostgreSQL database include:
- Advanced queries: Supabase supports complex SQL queries including joins, aggregations, and even full-text search.
- JSON support: PostgreSQL supports JSON data types, allowing you to work with both structured and unstructured data in the same database.
- Row-level security: With Supabase, you can implement fine-grained row-level access control, ensuring that users can only access the data they are authorized to see.
Additionally, the PostgreSQL database is fully integrated with the Supabase API, which means that every table you create in your database automatically generates RESTful endpoints to perform CRUD operations.
Therefore, this Instant API feature is a huge time saver for developers who would otherwise need to manually create endpoints to interact with their data.

Practical example: creating a table and accessing it via API in Supabase.
Imagine you are building a simple app that... to-do list (To-Do List).
- Node Supabase Dashboard, You create a table called tasks with the following columns:
- id (integer, primary key)
- title (text)
- done (Boolean, to indicate whether the task has been completed)
- id (integer, primary key)
- As soon as the table is created, Supabase automatically generates REST endpoints to interact with this data.
To find all the tasks:
GET https://YOUR-PROJECT.supabase.co/rest/v1/tasks
To add a new task:
POST https://YOUR-PROJECT.supabase.co/rest/v1/tasks
Content-Type: application/json
{
“title”: “Studying Supabase”,
“"done": false
}
- Access control can be configured directly on the panel, using Row Level Security (RLS).
- Example: each user can only view or edit their own tasks.
- Example: each user can only view or edit their own tasks.
This means that in just a few minutes, you already have one. complete relational database, with Ready-to-use API, authentication integrated and line-level security, without needing to program the backend manually.
2. Seamless API Integration with Supabase
One of the main strengths of this tool is its approach. API-first. Developers can interact with the backend exclusively through a RESTful API.
This makes it easier to integrate Supabase with different frontend technologies, such as React, Vue, Angular, and Next.js.
This separation of the frontend from the backend allows for greater flexibility, making it easier to change or update structures without having to review the entire backend.
Therefore, with the Supabase API, you can perform CRUD operations, manage user authentication, and handle file uploads and downloads. All this without needing to write complex server-side code.
The API is also well documented, making it easy for developers to get started. So whether you’re an experienced developer or just starting out, the straightforward documentation and SDKs make Supabase accessible and quick to implement.
Practical example of use with React.
Imagine you are developing a A React-based website for an online course community..
With the Supabase API, you can:
- Manage usersEach student creates their own account and logs in using email or Google, all controlled by Supabase authentication.
- List course contentsThe lessons are stored in the PostgreSQL database and are automatically displayed on the React frontend.
- Save progressWhen a student marks a lesson as completed, this information is recorded directly in the Supabase API, without needing to create a separate backend.
- Store filesPDFs or supporting materials are stored on Supabase and can be accessed by students via secure links.
Thus, React handles the interface, and Supabase delivers the complete backend via API (login, data, and files) without you needing to program servers.
3. User authentication made easy
Implementing user authentication is one of the most time-consuming and error-prone aspects of backend development. Supabase simplifies this process by providing a comprehensive, integrated authentication system.
This way, developers can implement secure user registration, login, and session management with just a few lines of code. Supabase supports multiple authentication methods, including:
- Email/Password: Traditional login with email and password.
- Social Logins: Authentication through popular services like Google, GitHub, and others.
- Magic Links: Password-free login via email.
In addition to handling login and registration, Supabase's authentication system also supports password resets, email verification, and JWT-based session management.

4. Real-time data synchronization
Real-time functionality is becoming increasingly important in modern applications. Supabase excels in this area by providing real-time data synchronization through PostgreSQL replication.
Therefore, with Supabase, you can easily create applications that react to changes in the database in real time.
For example, if you are creating a collaborative text editor, you can use the WebSocket-based event system to ensure that all users see the updates.
This feature is possible without any complex setup or configuration. So once your database is connected to Supabase, you can start listening for changes in real time using the client libraries.
5. Hassle-free file storage
In addition to handling database operations, Supabase also offers file storage. This feature is especially useful for applications that need to store and manage user-generated content.
Supabase's storage system is secure and comes with built-in access control policies. You can create public and private buckets to manage your files.
In addition, the Supabase API allows you to easily upload, download, and delete files programmatically.
6. Supabase Edge Functions for Serverless Execution
The tool also offers support for Edge Functions, which are lightweight, serverless functions that run at the edge, close to their users.
These functions offer low-latency execution, making them ideal for tasks that need to be performed quickly and efficiently.
Thus, with Supabase's edge functions, you can write custom server-side logic in JavaScript or TypeScript and deploy it directly to Supabase.
This feature is especially useful for tasks such as payment processing, sending transactional emails, or data transformations.
7. Scalability and security
As your application grows, Supabase scales with you. Because Supabase is built on PostgreSQL, it is designed to handle large volumes of data and high levels of concurrent traffic.
Security is another important consideration for any backend, and this tool implements best practices for data encryption, authentication, and access control.
Therefore, whether you're managing sensitive user data or protecting file uploads, Supabase ensures your application remains safe and secure.

Is Supabase worth using?
Supabase is an incredibly powerful tool for developers who want to simplify backend development while still having access to a scalable, secure, and feature-rich infrastructure.
By offering a managed PostgreSQL database, user authentication, real-time synchronization, file storage, and cutting-edge functions, this tool provides a comprehensive solution for building modern applications.
So, if you’re looking for an open-source alternative or simply want to simplify your backend development, Supabase is definitely worth exploring.
Finally, if you want to know how to get the most out of this tool, you need to be part of the NoCodeIA Training! Come and discover everything about the world NoCode with us!
FAQ – Frequently Asked Questions
What is Supabase used for?
Supabase is used to create the backend of modern applications with databases, authentication, APIs, and storage, all ready to go without needing to program the server from scratch.
Is Supabase free?
Yes, there is a free plan with usage limits, ideal for small projects or testing.
Which is better, Firebase or Supabase?
It depends on the project: the firebase It's great for fast apps and NoSQL databases; Supabase is better for those who want SQL (PostgreSQL) and more flexibility.