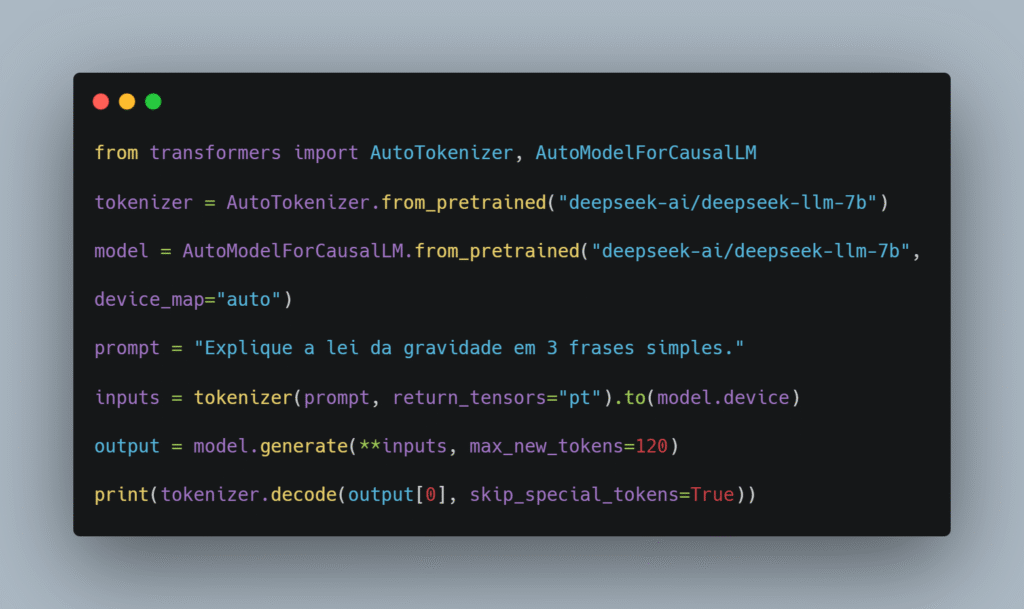
THE engenharia de prompt – ou prompt engineering – é, hoje, a habilidade‑chave para extrair inteligência prática de modelos generativos como o GPT‑4o. Quanto melhor a instrução, melhor o resultado: mais contexto, menos retrabalho e respostas realmente úteis.
Dominar esse tema expande a criatividade, acelera produtos digitais e abre vantagem competitiva. Neste guia, você entenderá fundamentos, metodologias e tendências, com exemplos aplicáveis e links que aprofundam cada tópico.

O que é Engenharia de Prompt?
THE engenharia de prompt consiste em projetar instruções cuidadosamente estruturadas para conduzir inteligências artificiais rumo a saídas precisas, éticas e alinhadas ao objetivo.
Em outras palavras, é o “design de conversa” entre humano e IA. O conceito ganhou força à medida que empresas perceberam a relação direta entre a clareza do prompt e a qualidade da entrega.
Desde chatbots simples, como o histórico ELIZA, até sistemas multimodais, a evolução sublinha a importância das boas práticas. Quer um panorama acadêmico? O guia oficial da OpenAI mostra experimentos de few‑shot learning and chain‑of‑thought em detalhes

Fundamentos Linguísticos e Cognitivos
Modelos de linguagem respondem a padrões estatísticos; portanto, cada palavra carrega peso semântico. Ambiguidade, polissemia e ordem dos tokens influenciam a compreensão da IA. Para reduzir ruído:
— Use termos específicos em vez de genéricos.
— Declare idioma, formato e tom esperados.
— Dívida contexto em blocos lógicos (strategy chaining).
Esses cuidados diminuem respostas vagas, algo comprovado por pesquisas da Stanford HAI que analisaram a correlação entre clareza sintática e acurácia de output.
Quer treinar essas práticas com zero código? A AI Agent and Automation Manager Training traz exercícios guiados que partem do básico até projetos avançados.
Metodologias Práticas de Construção de Prompts
Prompt‑Sandwich
A técnica Prompt-Sandwich consiste em estruturar o prompt em três blocos: introdução contextual, exemplos claros de entrada e saída, e a instrução final pedindo que o modelo siga o padrão.
Esse formato ajuda a IA a entender exatamente o tipo de resposta desejada, minimizando ambiguidades e promovendo consistência na entrega.
Chain‑of‑Thought Manifesto
Essa abordagem induz o modelo a pensar em etapas. Ao pedir explicitamente que a IA “raciocine em voz alta” ou detalhe os passos antes de chegar à conclusão, aumentam-se significativamente as chances de precisão – especialmente em tarefas lógicas e analíticas.
Pesquisas da Google Research comprovam ganhos de até 30 % na acurácia com essa técnica.
Critérios de Autoavaliação
Aqui, o próprio prompt inclui parâmetros de avaliação da resposta gerada. Instruções como “verifique se há contradições” ou “avalie a clareza antes de finalizar” fazem com que o modelo execute uma espécie de revisão interna, entregando saídas mais confiáveis e refinadas.
Para ver esses métodos dentro de uma aplicação mobile, confira o estudo de caso no nosso FlutterFlow course, onde cada tela reúne prompts reutilizáveis integrados à API da OpenAI.
Ferramentas e Recursos Essenciais
Além do Playground da OpenAI, ferramentas como PromptLayer fazem versionamento e análise de custo por token. Já quem programa encontra na biblioteca LangChain uma camada prática para compor pipelines complexos.
Se prefere soluções no‑code, plataformas como N8N permitem encapsular instruções em módulos clicáveis – tutorial completo disponível na nossa N8N Training.
Vale também explorar repositórios open‑source no Hugging Face, onde a comunidade publica prompts otimizados para modelos como Llama 3 e Mistral. Essa troca acelera a curva de aprendizado e amplia o repertório.
Casos de Uso em Diferentes Setores
Customer Success: prompts que resumem tíquetes e sugerem ações proativas.
Marketing: geração de campanhas segmentadas, explorando personas construídas via SaaS IA NoCode.
Saúde: triagem de sintomas com validação médica humana, seguindo diretrizes do AI Act europeu para uso responsável.
Educação: feedback instantâneo em redações, destacando pontos de melhoria.
Perceba que todos os cenários começam com uma instrução refinada. É aí que a engenharia de prompt revela seu valor.

Tendências Futuras da Engenharia de Prompt
O horizonte aponta para prompts multimodais capazes de orquestrar texto, imagem e áudio em uma mesma requisição. Paralelamente, surge o conceito de prompt‑programming, onde a instrução se transforma em mini‑código executável.
Arquiteturas open‑source como Mixtral estimulam comunidades a compartilhar padrões, enquanto regulamentações exigem transparência e mitigação de vieses.
O estudo da Google Research sinaliza ainda que prompts dinâmicos, ajustados em tempo real, impulsionarão agentes autônomos em tarefas complexas.
Resultados Práticos com Engenharia de Prompt e Próximos Passos Profissionais
THE engenharia de prompt deixou de ser detalhe técnico para se tornar fator estratégico. Dominar princípios linguísticos, aplicar metodologias testadas e usar ferramentas certas multiplica a produtividade e a inovação – seja você fundador, freelancer ou intraempreendedor.
Pronto para elevar suas habilidades ao próximo nível? Conheça a SaaS IA NoCode Training da No Code Start Up – um programa intensivo onde você constrói, lança e monetiza produtos equipados com prompts avançados.