Imagine you have a super-intelligent assistant trained based on all the knowledge available on the internet. However, when it comes to information specific to your business, it may not have direct references. So, how do you overcome this limitation?
One of the most effective ways to improve your assistant's intelligence is to train it with custom data, such as documents, articles, and internal files.
This technique is known as RAG (Retrieval-Augmented Generation) and allows AI assistants to combine pre-existing knowledge with specific information to provide more accurate and useful answers.
Continue reading to better understand how this approach can transform the use of AI in your business.
How does RAG (Retrieval-Augmented Generation) work?

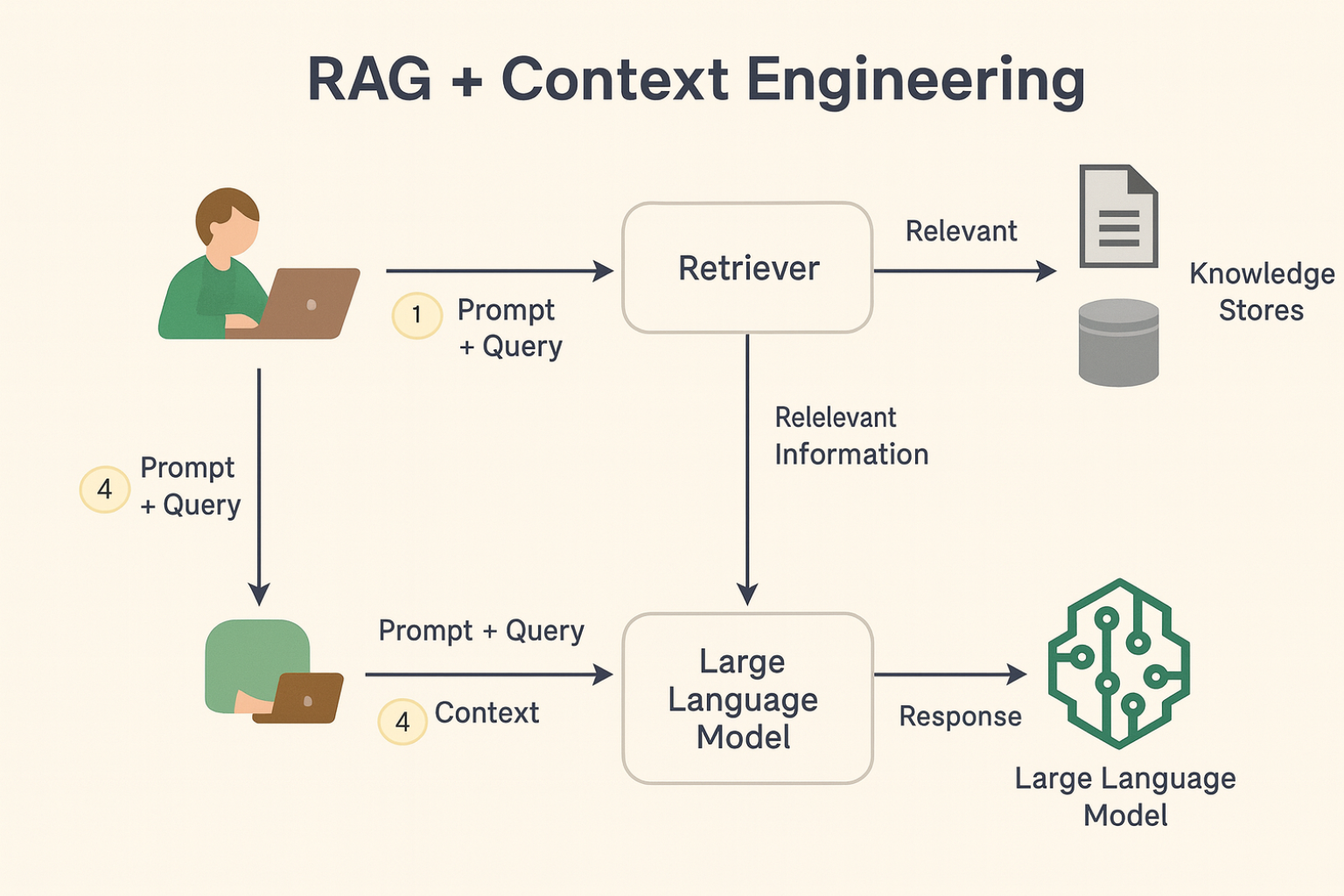
Now that we understand the concept of RAG (Retrieval-Augmented Generation), let's explore how it works in detail.
Unlike traditional AI assistants that simply generate answers based on previously trained knowledge, RAG searches for information from external sources and combines that data with its prior knowledge to provide more accurate and relevant answers.
The process can be divided into three main steps:
Ask the AI model
The user asks the AI assistant a question, just as they would in ChatGPT or another traditional chatbot.
Information Search (Retrieval)
The AI assistant queries a specific database, such as PDFs, websites, internal documents, or a business knowledge base. It retrieves the most relevant information to answer the question.
Augmented Generation
With the data retrieved, AI refines and structures the response by combining information from the knowledge base with its own linguistic model. This ensures a contextualized, accurate and relevant response.
This method is highly efficient as it allows AI to provide more personalized responses based on internal data. Additionally, the technology can leverage product documentation, support knowledge bases, and even company policies to ensure accurate and relevant information.

However, unlike a conventional chatbot, which responds based only on its original training, a RAG model can be constantly updated with new information, without the need for massive retraining.
In other words, this allows the AI to be highly dynamic and evolve progressively as new content is added, ensuring greater accuracy and relevance in responses.
For example, within the NoCode community, we provide assistants that use RAG to answer questions about tools such as make up, Diff, N8N and Bubble.
Furthermore, these assistants have been trained with specific documentation for these platforms, which allows them to provide even more detailed and accurate answers to students, thus facilitating learning and resolving technical queries.
5 Benefits of using RAG

Now that you understand how RAG works, let's explore the main benefits that this technology can bring to companies and users:
1. More accurate and contextualized responses
RAG enables AI assistants to query up-to-date information in real time, making responses more relevant and detailed.
2. Automation and efficiency
With the ability to access specific knowledge bases, AI reduces the need for constant human support, optimizing time and resources.
3. Continuous learning without the need for retraining
Unlike traditional AI models, which need to be constantly trained and retrained to learn new information, RAG can simply query updated databases.
4. Customization for different businesses
Companies can tailor AI to answer industry-specific questions by training the assistant with technical manuals, internal knowledge bases, and other relevant documents.
5. Applying RAG in customer support
In addition to academic and educational use, companies across a variety of sectors are using RAG to improve customer support.
Imagine a technology company that sells complex softwares. Customers frequently contact support with questions about specific features.
With an AI assistant trained with RAG, a company can feed the AI with its internal knowledge base, technical manuals, and FAQs. This allows the agent to answer questions accurately and quickly, helping to reduce the need for human intervention and streamline customer support.
How to apply RAG in your business?
Companies from different segments can take advantage of this technology to improve internal processes, customer service and task automation. Below, check out some practical strategies for applying RAG to your business.
1. Identify your company's main needs
Before integrating RAG, evaluate which areas of your business can benefit from this technology. Ask yourself the following questions:
- Does customer support receive a lot of repetitive questions?
- Does your team need to access technical documents frequently?
- Is there a large database that could be better utilized?
- Could internal training be optimized with an AI assistant?
2. Choose the right data sources
The great advantage of RAG is its ability to search for information from external sources. To ensure accurate and reliable answers, it is essential to select the best data repositories. Some options include:
- technical documentation and product manuals;
- FAQs and internal knowledge bases;
- articles, research and case studies;
- structured data from CRMS and ERPS;
- pdf files, spreadsheets and notion.
3. Integrate RAG with your existing tools
For best results, RAG should be connected to the platforms your team already uses. Some ways to integrate include:
- Chatbots and virtual assistants: AI trained to answer recurring questions and provide technical support;
- Management systems (CRM/ERP): AI can access customer data to provide more personalized responses;
- E-learning and corporate training: intelligent assistants that help employees access learning materials quickly;
- E-commerce and customer service: chatbots that check inventory, return policies and product recommendations.
4. Evaluate and optimize
Implementing RAG doesn’t end with the initial setup. It’s essential to monitor AI performance by analyzing metrics such as:
- response accuracy rate;
- user satisfaction;
- reduction of service time;
- most frequently asked questions and opportunities for improvement.
With this information, you can improve the AI database and ensure that the answers become increasingly accurate.
Conclusion
Whether it’s to improve customer support, automate processes or optimize internal knowledge management, RAG is a powerful and affordable solution for companies in different segments.
With this technology, AI agents can access specific knowledge bases, improve the user experience and reduce the need for extensive training.
If you want to learn how to create intelligent AI assistants using N8N, check out NoCode Startup's complete course. In it, you will have access to practical training on automation and data integration to make your business' AI even more efficient.
Explore more about the N8N Course – NoCode Startup and start transforming your company with artificial intelligence!