Introducción al modelado de datos
Ciertamente el tema de Modelado de Datos y SQL es uno de los temas más importantes cuando queremos desarrollar sistemas o aplicaciones robustas.
La estructuración del modelado de datos SQL de su aplicación puede marcar la diferencia en el futuro, ahorrando trabajo y brindando mucho rendimiento y escalabilidad.
Este contenido de Modelado de datos y SQL explicará los fundamentos más importantes de la base de datos y presentará una metodología paso a paso para estructurar los datos de su negocio y convertirlos en una aplicación.
Mira el contenido completo del video aquí:
¿Que aprenderás?
- Fundamentos de modelado de datos y SQL
- Metodología cómo modelar tu base de datos
- Modelo Conceptual, Lógico y Físico en la práctica
- Cómo crear una aplicación a partir de su modelo de base de datos
Fundamentos de la base de datos
Antes de entrar en el tema de las Bases de datos, es necesario comprender algunos conceptos importantes:
- Die: Un valor en su forma individual
- Base de datos: Conjunto de datos organizados y relacionados entre sí
- Información: información importante de una base de datos que ayuda a tomar decisiones estratégicas
- ¿Cuántos cursos vendió en el mes?
- ¿Cuáles son los mejores meses del año para las ventas?
Para administrar y manipular datos en un sistema, generalmente usamos un Sistema de administración de base de datos, los más famosos son:
- mysql
- No SQL
- MongoDB
- base de fuego
Para comprender la diferencia entre ellos, debe comprender qué son las bases de datos relacionales y qué es SQL.
Bases de datos relacionales y SQL
Las bases de datos relacionales son bases de datos que almacenan y manipulan datos relacionados entre sí.
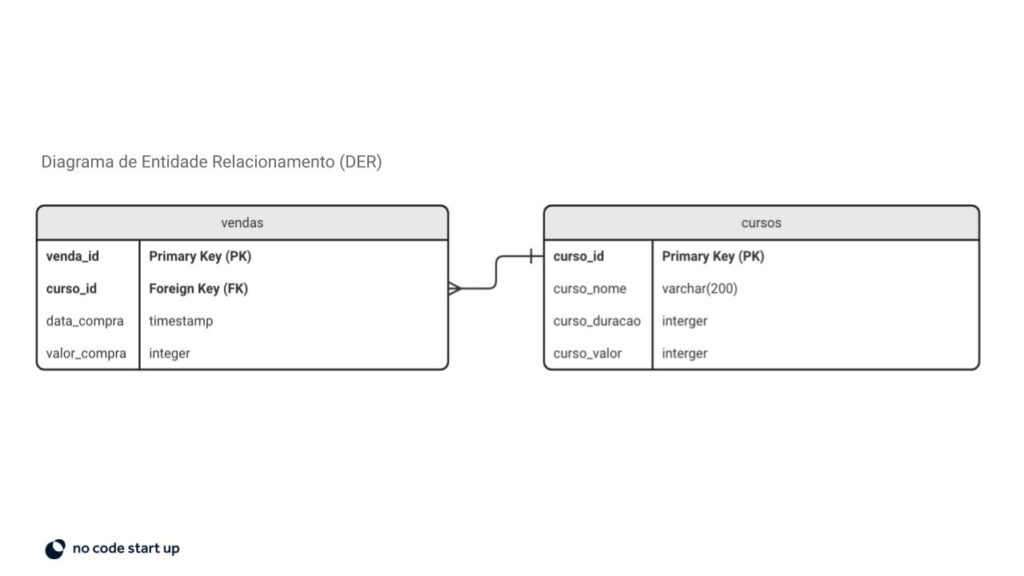
Las tablas generalmente se conectan a través de una clave principal y externa. La clave principal (PK) es el identificador de ese registro en la tabla y debe ser único.
La clave externa (Foreign Key – FK) es la clave principal de otra tabla, por lo que podemos conectar los datos.
Las bases de datos más famosas del mercado son PostgreSQL, MySQL y SQLite.
Para manipular la información en la base de datos usamos SQL, que es como hacemos consultas en nuestra base de datos.

Bases de datos no relacionales y NoSQL
NoSQL significa No Sólo SQL, lo que muestra que las bases de datos NoSQL pueden o no tener relaciones.
Hay varias formas de estructurar nuestros datos:
- documento y colección
- gráficos
- Valor clave
- De columna
Nuestro enfoque será el documento y la colección... donde almacenamos datos en "carpetas" que son colecciones y "documentos" que son registros.

Las principales bases de datos NoSQL del mercado son MongoDB, Firebase y Cassandra.
El enfoque de este contenido estará en SQL, vea nuestro contenido de modelado de datos NoSQL más adelante.
Metodología para el Modelado de Datos
Para realizar el modelado de datos desde cero, debe seguir estos pasos:
- Levantamiento de requisitos;
- Modelo conceptual;
- Modelo Lógico'
- Modelo físico.
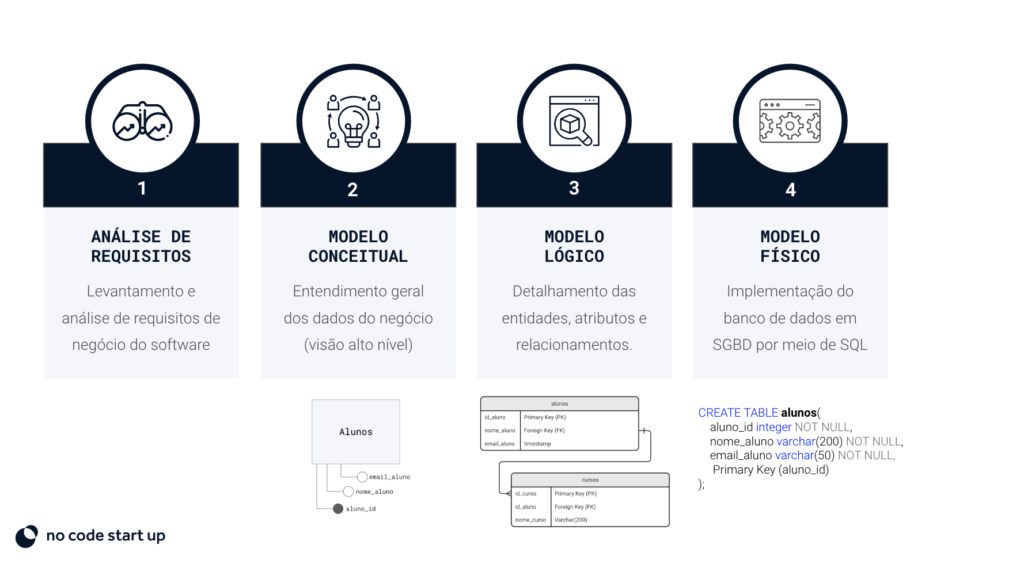
En la etapa de análisis de requerimientos se realiza un levantamiento de todas las funcionalidades que hará el software, las cuales deben estar alineadas de acuerdo a la visión del usuario final.
En este contenido de modelado de datos, no será el enfoque explicar la parte de recopilación de requisitos, pero podría ser una clase futura aquí.
¿Empecemos?
¡Comencemos con el modelo conceptual!
Paso 1 Modelado de datos: modelo conceptual
Para realizar el modelado de la base de datos, usaremos como ejemplo el caso de No-Code Start-Up, aquí en nuestra comunidad tenemos nuestros Training (cursos) y los estudiantes pueden comprar estos cursos.
Vamos a entender cómo modelar?
La primera etapa es el Modelo Conceptual, donde entendemos el concepto general del negocio y cuáles serán los principales datos involucrados. Realizaremos las siguientes acciones:
- Definir entidades
- Establecer atributos
- Definir relaciones
- Construir el modelo conceptual final - Diagrama de relación de entidad (ERD)
Las entidades son todas las tablas principales involucradas, como "Estudiantes", "Cursos" y "Ventas". Los atributos son los campos que tendremos en estas tablas, el diseño se verá así:

A partir de ahí podemos definir cómo se relacionan las entidades, para eso tenemos algunas opciones:
- relación 1 a 1
- Relación de 1 a muchos
- Relación de muchos a muchos
Ver algunos ejemplos
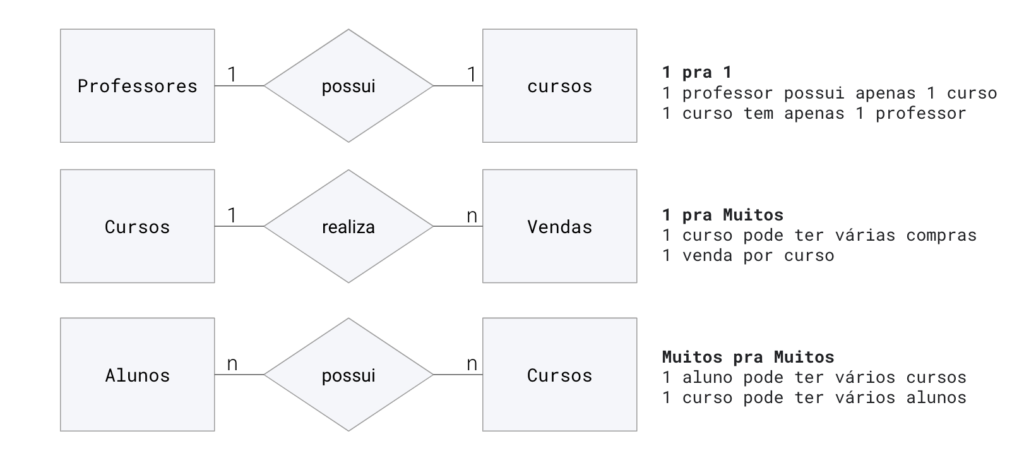
Por lo tanto, nuestro modelo conceptual final se verá así:

Paso 2 Modelado de datos: modelo lógico
En el Modelo Lógico, detallaremos más las entidades y atributos. También diseñaremos los esquemas y sus relaciones.
Antes de continuar, debemos asegurarnos de que estamos de acuerdo con las 3 formas normales.
La normalización es la optimización que realizamos en las tablas para reducir la redundancia, la duplicación y la inconsistencia de los datos.
De esta manera podemos tener un modelo de datos más consistente, organizado y con mejor rendimiento.
- NF1: la tabla debe tener solo atributos únicos, no puede haber atributos multivaluados.
- NF2: los atributos (sin clave) dependen solo de la clave principal
- NF3: los atributos (no clave) deben ser independientes entre sí
Mire el video de YouTube sobre modelado de datos para comprenderlo con ejemplos reales.
A partir de la normalización de datos, podemos pasar al diseño de esquemas y sus relaciones. El dibujo final se verá así:
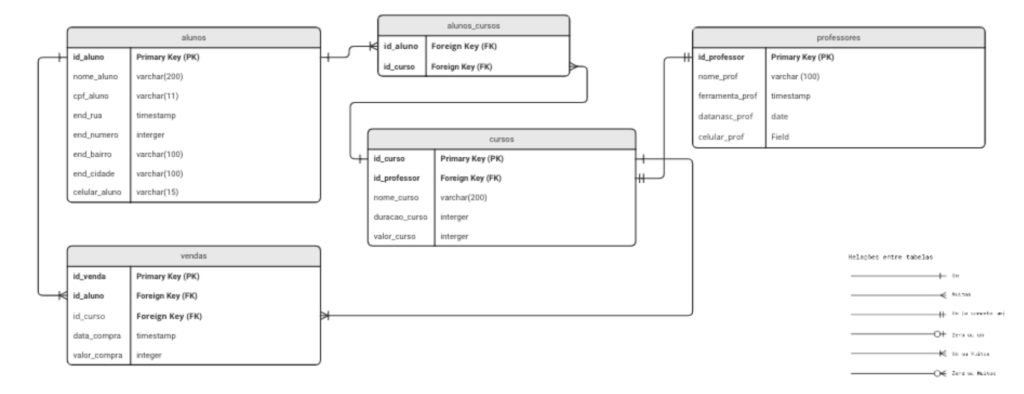
Paso 3 Modelado de datos: modelo físico
El paso 3 es donde damos vida a nuestro modelado de datos, debemos elegir uno de los DBMS en el mercado para crear nuestra base de datos. Consta de 3 acciones:
- Elección de la tecnología DBMS
- Crear base de datos con SQL
- Gestión y mantenimiento del banco.
Crearemos todas las tablas desde SQL.
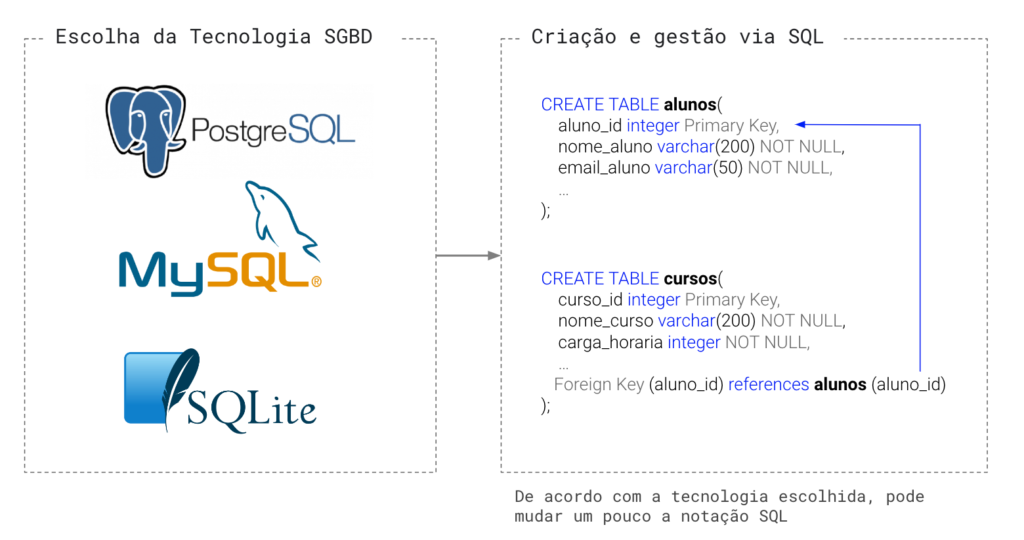
finalización
Espero que haya disfrutado este contenido de modelado de datos, para obtener más detalles, vea nuestro video completo donde creamos una aplicación a partir de nuestra base de datos preparada. La aplicación creada está hecha en 100% sin programación, con Bubble.
Si quieres saber más sobre el mundo nocode, entiende Cómo crear una aplicación sin código.
¡Hasta la próxima!
Matheus Castelo
Curso de Startup sin código: