Learn once and for all how to plan your application development project, which steps you cannot miss in your planning and, on top of that, learn about some tools that can help in this process.
Many developers start their projects without a clear plan. The result? Delays, rework, and lost money.
In this guide, you will learn about the 7 essential planning phases before starting to develop an app, whether with no-code tools like Bubble or FlutterFlow, or with traditional code.
Table of Contents
There is a lot of planning that can be done before we even open the platform that we are going to use to develop our application.
Be with Bubble, FlutterFlow, WeWeb, AppGyver, any nocode tool or even (and especially) with code.
We divided our planning into 7 phases, which I will present here for you now, let's show this visually to you.
In the end, I still want to present to you some tool tips that can help us a lot in some of these phases.
Phase 0 – Define your app concept
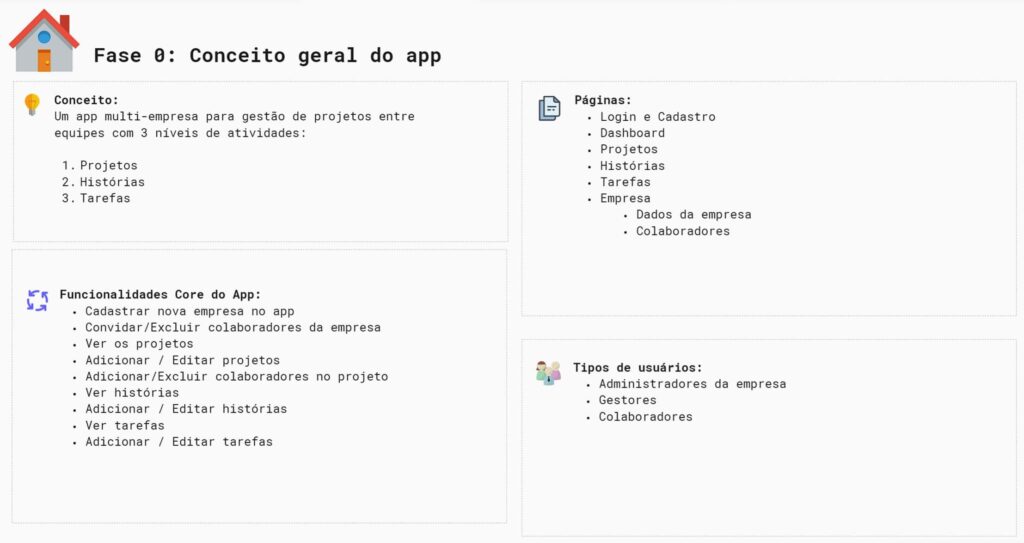
Phase zero is the general conceptualization phase of the application, that is, here we will define exactly what our app is, what its objective is, what it does, etc…
Here you define:
- The purpose of the app
- Who will be the target audience?
- What problems does it solve?
- What features does it need to have?
This phase is extremely important as it will be the basis for all the others.
Everything comes from this conceptualization, which is why this mapping must be extremely well done and aligned with the client or anyone involved in the project.
In the end, this ends up practically becoming a scope of the project, what will be done and what is expected.
Here, as an example, I brought some of the points that can be raised at this stage of planning the application:
App concept: in this case we are talking about a multi-company project management app.
We can collect requirements, or basically functions of our app. Listing what we expect the app to do.
(We have some content about requirements gathering, which you can see here on our blog or on our YouTube channel.)
We can list the pages that our app will have, type of users, user permissions and so on.
I believe you understand the importance of this step, right? Our entire app will be based on what we collect and write down here.
Phase 1 – Look for references and get inspired by other apps
Research apps that do something similar to what you want to create. The goal is to understand usability patterns, design, and navigation flow.
Useful examples: ClickUp, Asana, Notion. Take a look at how the login screens, dashboard, registrations, and user interactions work.
In design there is a law called Jakob's Law – which says:
“People spend most of their time on other websites and prefer their website to work in the same way as all the other websites they already know”
In other words, users expect their website, app, system to have usability similar to the other apps that exist.
Important point: the idea here is to inspire us, NOT COPY.
Here in our example, we are creating a project manager and we already know the pages we are going to develop. This way we can look for inspiration in similar applications.
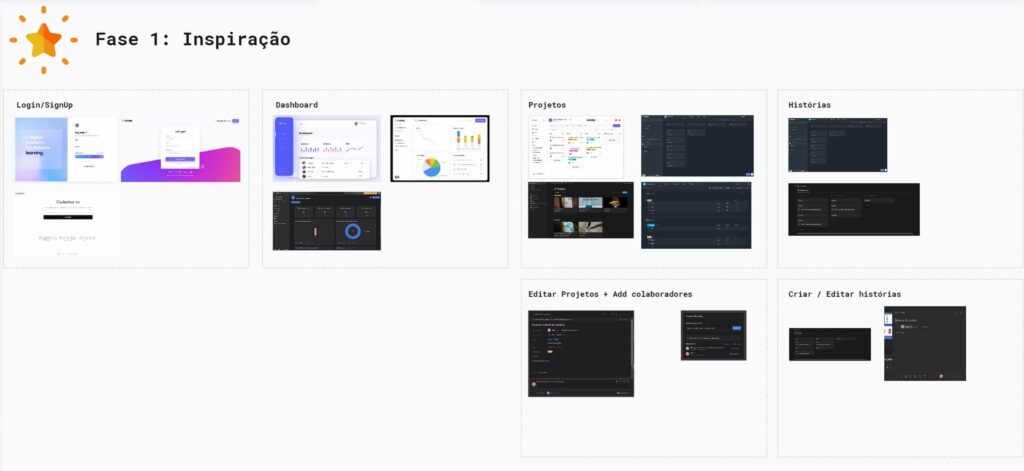
We brought here some inspiration for registration and login flows.
Some inspirations on how some project management systems like ClickUp or Asana show their projects to users and so on.
This way we begin to have an idea of how the market already does what we are trying to do, we can be inspired and, on top of that, improve the UX.
Now that we know the pages we are going to develop, what our app needs to do and we also have some inspiration, we can start designing our Wireframes
Phase 2 – Create low-fidelity wireframes
At this stage, you sketch out the structure of the application screens, without worrying about colors or visual identity.
The objective is:
- Get quick feedback from stakeholders
- Visualize the user journey
- Validate the main elements of each screen
This step is crucial, because with it we can start to visualize the face of our application and we can also get quick and objective feedback from those involved in the project.
With Wireframes we can remove distractions such as colors, design and focus on collecting feedback exactly about what matters at that moment, layout and usability.
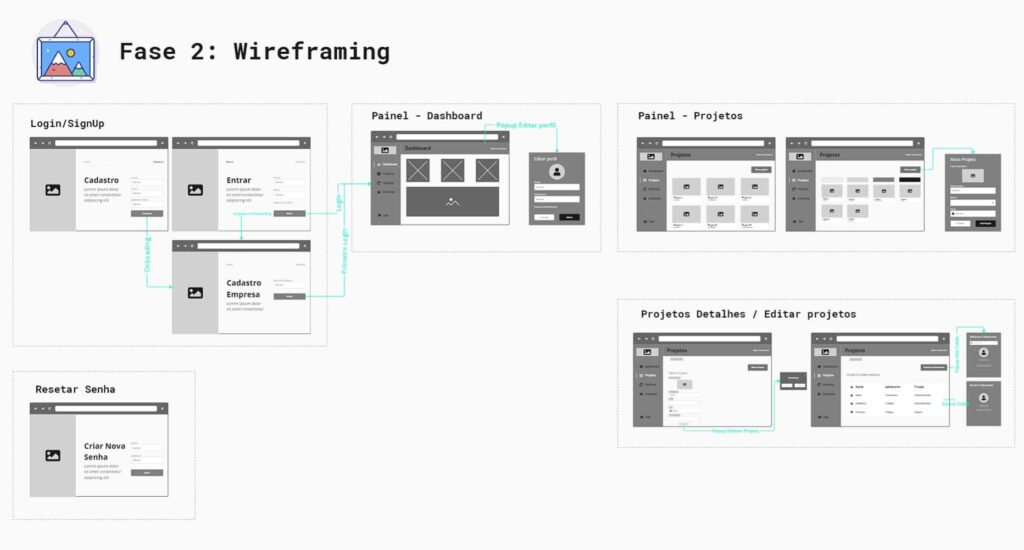
Here in our example, we can already see what our login flow will look like, how our dashboard will be laid out and so on.
Phase 3 – User Flows
This phase is very common to be executed in parallel with wireframing and aims to document and detail all the action flows that each user can perform on the screens in question. This step defines the user's navigation between screens and functionalities.
We detail all actions, permissions and restrictions considering each type of user for each screen or page.
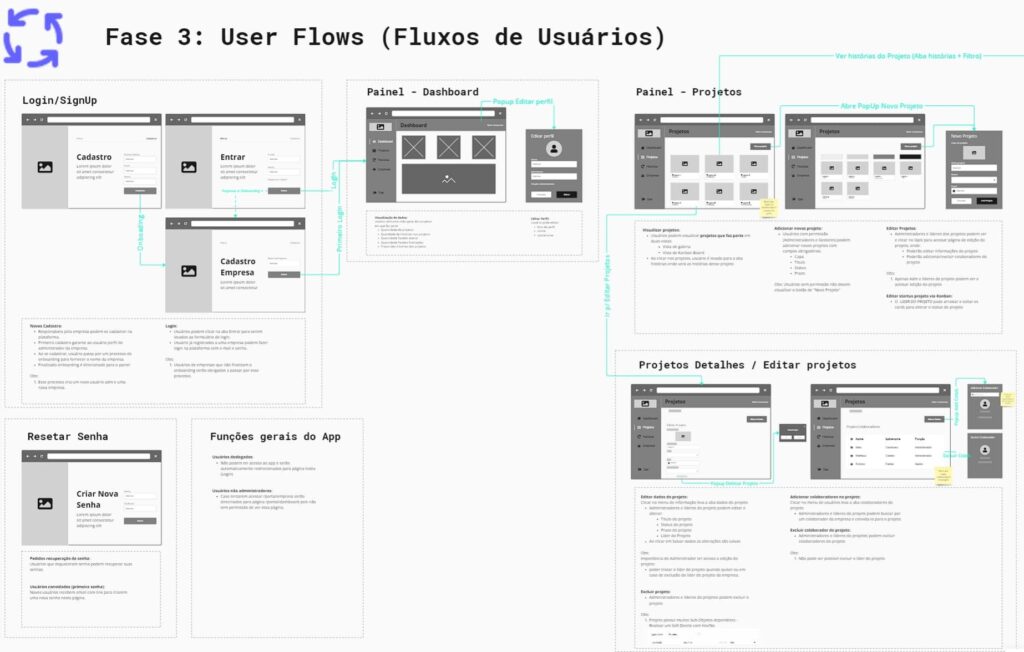
In our example here, on our login page, we detail the flows:
- New Registrations
- Login
Phase 4 – Data Modeling
I believe that this phase does not require such an important comment.
Data modeling is the heart of any application and must be done before we think about jumping into any platform to start development.
This is what differentiates apps which will work well when it has more users from apps which will not.
Without good data modeling, applications are already destined to cause major problems in the future. Failures at this stage can cause slowdowns, reduced performance, and in some cases the solution will be a complete refactoring of the app.
Since data is the heart, you end up building your app based on data modeling. The logic ends up being thought out according to what was designed.
That's why it's important to invest a good amount of time in this modeling before even thinking about using the tool.
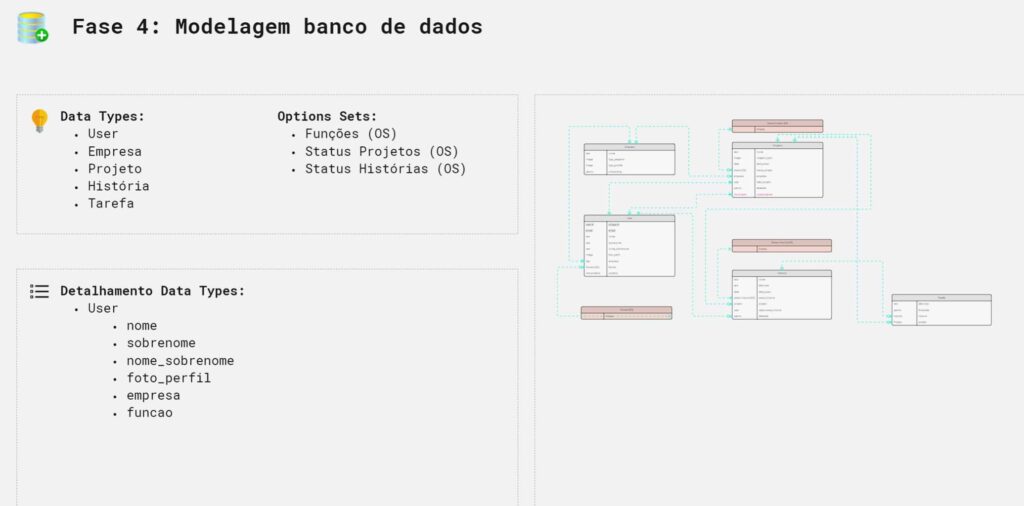
Here in our example we can see which tables will be needed in our app, which fields we will have in each table and how they relate to each other.
Here our objective is not to teach how to do data modeling, however we have two free courses on YouTube on the topic, one on relational data modeling and another about non-relational data modeling, I highly recommend you watch it, I'll leave the video cards listed here.
Phase 5 – Security
This is the most underestimated phase by all novice users and even some users with years of experience. It is a bureaucratic step, but extremely necessary and should also ideally be thought about before we start developing our apps, as there may be cases where we need to remodel some fields in our database in order to implement the expected security in our app.
In practice, this implementation varies from tool to tool, but at a conceptual level, the idea is the same.
Think of permissions like: 'user can only view their own data' or 'admin can edit company data'.
By doing this mapping, then we just need to implement it in our systems.

In our example, I passed Data Type by Data type and implemented the necessary rules to ensure that only those who can actually see the data are the only ones with access to it.
Phase 6 – Visual Identity + High Fidelity Prototyping
Now it's finally time to think about the design of our application.
At this stage we define the entire color palette of the project, default styles, fonts, etc… And we implement this in our application, based on what we have already built in our wireframes.
Tools like Figma allow you to create navigable prototypes, ideal for validation with clients.

It is important and interesting to comment here that if we stop to analyze, practically in all the phases mentioned here, we can carry out micro validations with our clients, this way we will advance the project little by little, with the client's approval.
This completely mitigates rework in more advanced stages of development, which take much longer to adjust.
Here are some tool suggestions
General Planning:
Inspirations:
Wireframing:
- Miro
- Figma
UserFlows
Now that you know the 7 phases of application planning, you can start structuring your project with more confidence and organization.
These steps are not bureaucracy, they are the basis for an app that works, grows and can be quickly validated with real users.
These examples that I gave here in this video are from a complete track that we have in NoCode StartUp Bubble formation, where I detail each of these topics step by step with you and later we build this Project Management application together.
Thank you, big hug and see you next week!
Additional Content: