O DeepSeek virou um dos temas mais comentados de 2025. Mesmo para quem já acompanha os LLMs (Large Language Models), ainda há muito a descobrir sobre a proposta da equipe chinesa e, principalmente, como aplicar hoje em projetos de NoCode e IA, sem complicar.

Conteúdo
Resumo rápido: O DeepSeek oferece uma família de modelos open‑source (7 B/67 B parâmetros) licenciados para pesquisa, um braço especializado em geração de código (DeepSeek Coder) e uma variante de raciocínio avançado (DeepSeek‑R1) que rivaliza com pesos‑pesados, como GPT‑4o, em lógica e matemática. Ao longo deste artigo você descobrirá o que é, como usar, por que ele importa e oportunidades no Brasil.
O que é o DeepSeek?
Em essência, o DeepSeek é um LLM open‑source (para pesquisas da comunidade) desenvolvido pela DeepSeek‑AI, laboratório asiático focado em pesquisa aplicada. Lançado inicialmente com 7 bilhões e 67 bilhões de parâmetros (7B/67B), o projeto ganhou notoriedade ao liberar checkpoints completos no GitHub, permitindo que a comunidade:
- Baixe os pesos sem custo para fins de pesquisa;
- Faça fine‑tuning local ou em nuvem;
- Incorpore o modelo em aplicativos, agentes autônomos e chatbots.
Isso o coloca no mesmo patamar de iniciativas que priorizam transparência, como LLaMA 3 da Meta. Se você ainda não domina os conceitos de parâmetros e treinamento, confira nosso artigo interno “O que é um LLM e por que ele está mudando tudo” para se situar.
A inovação do DeepSeek LLM Open‑Source
O diferencial do DeepSeek não está apenas na abertura do código. O time publicou um processo de pré‑treino em 2 trilhões de tokens e adotou técnicas de curriculum learning que priorizam tokens de maior qualidade nas fases finais. Isso resultou em:
- Perplexidade inferior a modelos equivalentes de 70 B parâmetros;
- Desempenho competitivo em benchmarks de raciocínio (MMLU, GSM8K);
- Licença mais permissiva que rivaliza com Apache 2.0.
Para detalhes técnicos, veja o paper oficial no arXiv e o repositório DeepSeek‑LLM no GitHub
DeepSeek‑R1: o salto em raciocínio avançado
Poucos meses após o lançamento, surgiu o DeepSeek‑R1, uma versão “refined” com reinforcement learning from chain‑of‑thought (RL‑CoT). Em avaliações independentes, o R1 atinge 87 % de acurácia em prova de matemática básica, superando nomes como PaLM 2‑Large.
Esse aprimoramento posiciona o DeepSeek‑R1 como candidato ideal para tarefas que exigem lógica estruturada, planejamento e explicação passo a passo – requisitos comuns em chatbots especialistas, assistentes de estudo e agentes autônomos IA.
Se você deseja criar algo parecido, vale dar uma olhada na nossa Formação Gestor de Agentes e Automações IA, onde mostramos como orquestrar LLMs com ferramentas como LangChain e n8n.

DeepSeek Coder: geração e compreensão de código
Além do modelo de linguagem geral, o laboratório lançou o DeepSeek Coder, treinado em 2 trilhões de tokens de repositórios GitHub. O resultado? Um LLM especializado capaz de:
- Completar funções em múltiplas linguagens;
- Explicar trechos de código legado em linguagem natural;
- Gerar testes unitários automaticamente.
Para equipes freelancer e agências B2B que prestam serviços de automação, isso significa aumentar produtividade sem inflar custos. Quer um caminho prático para integrar o DeepSeek Coder aos seus fluxos? No curso Xano para Back‑ends Escaláveis mostramos como conectar um LLM externo ao pipeline de build e gerar endpoints inteligentes.
Como usar o DeepSeek na prática
Mesmo que você não seja um engenheiro de machine learning, há formas acessíveis de experimentar o DeepSeek hoje.
1. Via Hugging Face Hub
A comunidade já espelhou os artefatos no Hugging Face, permitindo inferência gratuita por tempo limitado. Basta um token HF para rodar chamadas transformers locais:
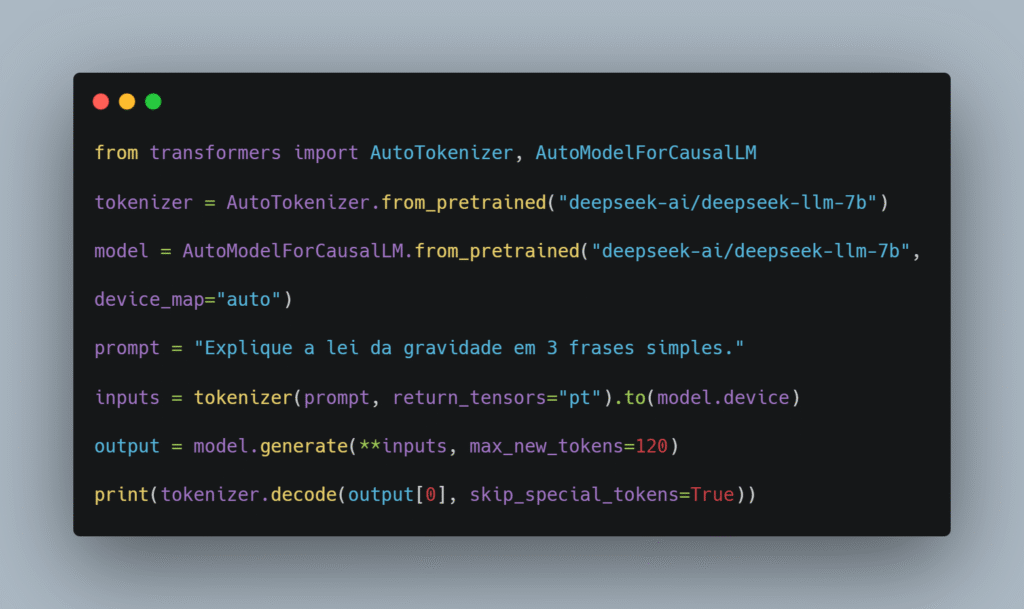
Dica: Se o modelo não couber na sua GPU, use quantização 4‑bit com BitsAndBytes para reduzir memória.
2. Integração NoCode com n8n ou Make
Ferramentas de automação visual como n8n e Make permitem chamadas HTTP em poucos cliques. Crie um workflow que:
- Recebe input de formulário Webflow ou Typeform;
- Envia o texto ao endpoint do DeepSeek hospedado na própria nuvem da empresa;
- Retorna a resposta traduzida para PT‑BR e envia via e‑mail ao usuário.
Essa abordagem dispensa backend dedicado e é perfeita para founders que desejam validar uma ideia sem investir pesado em infraestrutura.
3. Plugins com FlutterFlow e WeWeb
Caso o objetivo seja um front-end polido, você pode embutir o DeepSeek em FlutterFlow ou WeWeb usando HTTP Request actions. No módulo avançado do Curso FlutterFlow explicamos passo a passo como proteger a API key no Firebase Functions e evitar exposições públicas.

DeepSeek no Brasil: cenário, comunidade e desafios
A adoção de LLMs open‑source por aqui cresce em ritmo acelerado. Células de pesquisa na USP e na UFPR já testam o DeepSeek para resumos de artigos acadêmicos em português. Além disso, o grupo DeepSeek‑BR no Discord reúne mais de 3 mil membros trocando fine‑tunings focados em jurisprudência brasileira.
Curiosidade: Desde março de 2025, a AWS São Paulo oferece instâncias g5.12xlarge a preço promocional, viabilizando fine‑tuning do DeepSeek‑7B por menos de R$ 200 em três horas.
Casos de uso reais
- E‑commerce de nicho usando DeepSeek‑Coder para gerar descrições de produto em lote;
- SaaS jurídico que roda RAG (Retrieval‑Augmented Generation) sobre súmulas do STF;
- Chatbot de suporte interno em empresas CLT para perguntas sobre RH.
Para uma visão prática de RAG, leia nosso guia “O que é RAG – Dicionário IA”.
Pontos fortes e limitações do DeepSeek
Vantagens
Custo zero para pesquisa e prototipagem
Uma das maiores vantagens do DeepSeek é sua licença aberta para uso acadêmico e pesquisa. Isso significa que você pode baixar, testar e adaptar o modelo sem pagar royalties ou depender de fornecedores comerciais. Ideal para startups em estágio inicial e pesquisadores independentes.
Modelos enxutos que rodam localmente
Com versões de 7 bilhões de parâmetros, o DeepSeek pode ser executado em GPUs mais acessíveis, como a RTX 3090 ou mesmo via quantização 4-bit em nuvem. Isso amplia o acesso a desenvolvedores que não têm infraestrutura robusta.
Comunidade ativa e contribuinte
Desde seu lançamento, o DeepSeek acumulou milhares de forks e issues no GitHub. A comunidade vem publicando notebooks, fine-tunings e prompts otimizados para diferentes tarefas, acelerando o aprendizado coletivo e a aplicação em casos reais.
Limitações
- License research‑only ainda impede uso comercial direto;
- Ausência de suporte oficial para PT‑BR no momento;
- Necessidade de hardware com 16 GB VRAM para inferência confortável.

Próximos passos aprendendo e construindo com o DeepSeek
Próximos passos: aprendendo e construindo com o DeepSeek
Entendendo o que você aprendeu
Se você acompanhou este artigo até aqui, já tem uma visão ampla sobre o ecossistema DeepSeek. Conhece os diferentes modelos da família, seus diferenciais em relação a outros LLMs, e tem caminhos claros para aplicação prática, mesmo sem background técnico.
Consolidando os principais conceitos
DeepSeek: o que é?
Trata-se de um LLM open-source com diferentes variantes (7B/67B parâmetros), disponibilizado para pesquisa e experimentação. Ganhou destaque pela combinação de abertura, qualidade de treinamento e foco em especializações como código e raciocínio.
A principal inovação
Sua abordagem de pré-treinamento com 2 trilhões de tokens e estratégias como curriculum learning permitiram que mesmo o modelo de 7B se aproximasse do desempenho de alternativas maiores e mais caras.
Como usar DeepSeek
Desde chamadas diretas por API até fluxos automatizados via Make, n8n ou ferramentas front-end como WeWeb e FlutterFlow. A documentação e a comunidade ajudam a acelerar essa curva.
Oportunidades no Brasil
A comunidade DeepSeek está se consolidando rápido por aqui, com aplicações reais em pesquisa acadêmica, SaaS, e-commerces e times que buscam produtividade via IA.
Avançando com apoio especializado
Se você quer acelerar sua jornada com IA e NoCode, a NoCode Start Up oferece formações robustas com foco em execução real.
Na Formação SaaS IA NoCode, você aprende como usar LLMs como o DeepSeek para criar produtos de verdade, vendê-los e escalar com liberdade financeira..