Nowadays, technology has become essential for the growth of any business. The development of business applications, and knowing how much to charge per application, stands out as one of the biggest opportunities of the decade, offering a vast field for freelancers and software house agencies.
Creating apps for different niches can be highly profitable. For example, you can develop a delivery app for local restaurants, a scheduling app for clinics, or even a software as a Service (SaaS) to solve specific problems in a given niche, charging a monthly fee for use. This last model, in fact, is one of the biggest opportunities in the area.
However, one of the biggest questions that arise among beginner developers is how much to charge for developing an application. Many do not know how to structure the project scope and set a fair price for delivery. In this post, we will explain in detail how you can calculate the value of an application and structure your entire project proposal.
Contents
Structuring the budget to know how much to charge
Developing an application is a complex and unpredictable task due to the numerous factors involved. The process includes everything from organizing data and users, gathering requirements, creating screens and flows, choosing appropriate technologies, and carrying out tests.
The most challenging factor, however, is understanding the customer's vision, who often does not know how to clearly express their needs. Often, clients come in with a vague idea and wait for the developer to turn it into reality, which can make project pricing quite challenging.
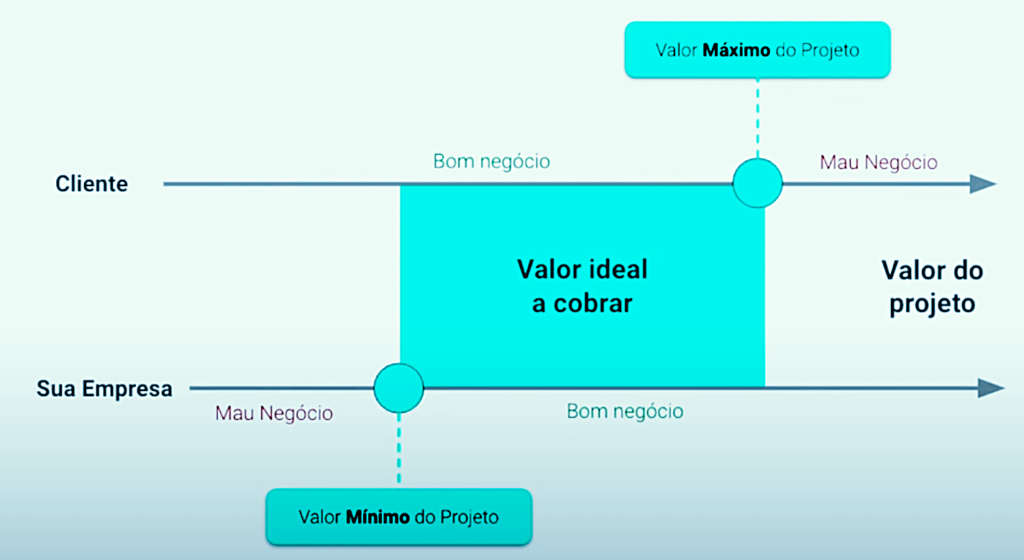
To correctly price a project, several factors must be considered, such as the developer's experience, market competition, type of client, among others. A pricing error can lead to financial losses, especially if the customer asks for additional features throughout development without paying extra for them. Additionally, poor initial communication can result in a problematic customer relationship.
Factors to consider when deciding how much to charge per application

Project Scope
The project scope is the most crucial part, as it defines all the requirements, delivery times, maintenance needs, complexity and costs involved. Requirements gathering must include both functional and non-functional requirements, screen design, navigation flow and technologies to be used. An accurate estimate of time and effort is essential for calculating the project cost.
Fixed and Variable Costs
Fixed costs include expenses such as rent, electricity, internet, and infrastructure necessary to maintain the operation. Variable costs, on the other hand, involve hiring third parties (designers, additional developers), tools and technologies specific to the project. Knowing these costs well is essential to calculate the minimum amount that covers all expenses and still generates profit.
Profit margin
The profit margin must be defined taking into account the market and the level of experience and authority of the developer or agency. Therefore, profit margins can vary between 20% and 50% depending on the type of project and financial expectations.
Client Type
Experience dealing with different types of customers also affects pricing. Customers with a clear vision of what they want generally facilitate the development process, allowing for more efficient and faster work. While undecided clients or those with little clarity may require more time and effort, justifying a higher value to compensate for these difficulties.
Billing Model: how to charge for your app
There are different billing models that can be applied:
- Fixed project billing: Ideal for projects with high predictability, where the scope is well defined.
- Hourly billing: Suitable for projects with less predictability, where the scope may change throughout development.
- Mixed model: Combines a fixed price for specific deliveries and hourly charging for new features or adjustments requested by the customer.
Estimating how much to charge per app
Finally, to reach the final value of the project, it is necessary to consider all the variables mentioned. First, map out all fixed and variable costs. Then, define your profit margin and estimate the time needed to complete the project based on the defined scope. Then, multiply the estimated time by your hourly rate and add the profit margin to obtain the final value.
Communicating with the customer
Good communication is essential to avoid misunderstandings and ensure all parties are aligned. Therefore, it is important to document all conversations and decisions in a very detailed contract, specifying the scope, deadlines, costs and payment conditions. This provides security for both the developer and the customer.
Continuous learning and feedback
For beginning developers, it's important to focus more on learning than initial financial gains. Therefore, working on smaller projects and asking for constant feedback from clients can provide valuable insights to hone your skills and better understand how to price future projects.
But after all, how much should I charge per application?
Developing applications is a lucrative opportunity, but it requires good planning and communication to avoid problems during the project. By understanding all the variables involved and correctly structuring the scope, you can price your work fairly and ensure customer satisfaction. Furthermore, invest in no-code development tools it can speed up the process and reduce costs, offering a competitive advantage in the market.
Bonus Tip
To further increase your earnings, consider developing applications for the international market. Therefore, learning English and working with foreign clients can be an excellent way to earn in dollars, taking advantage of the currency's appreciation. This way, you can charge more and significantly increase your revenue.