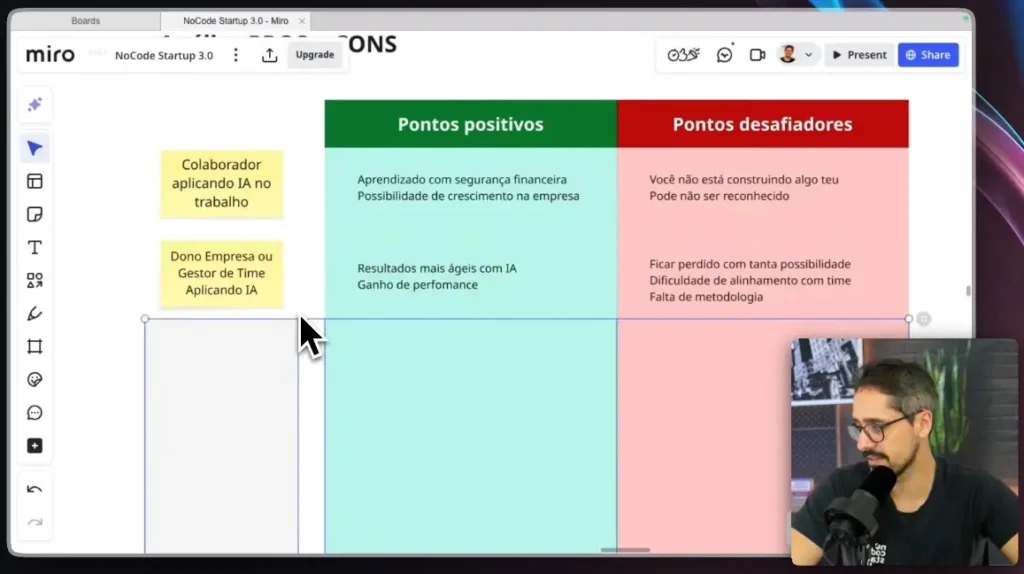
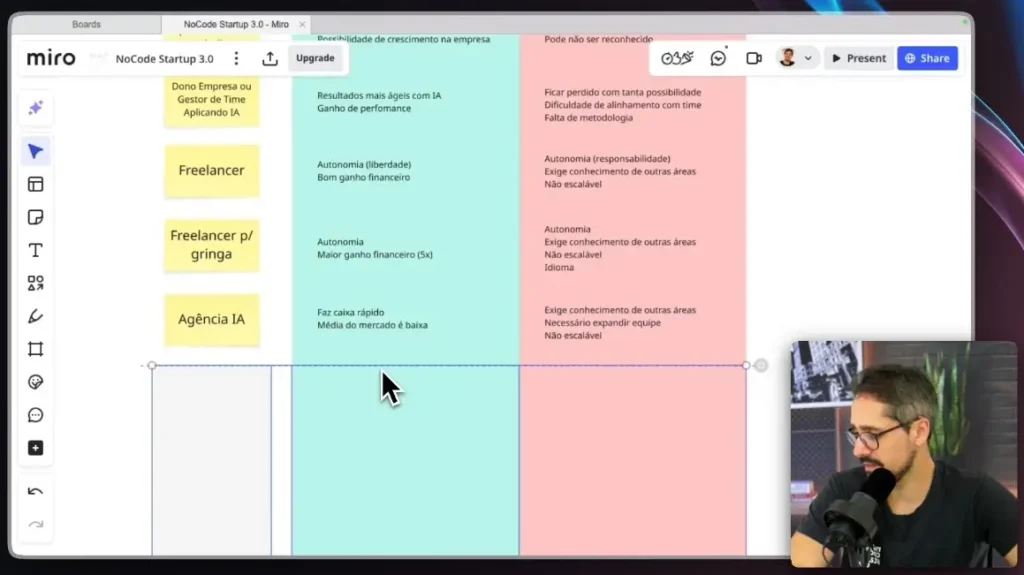
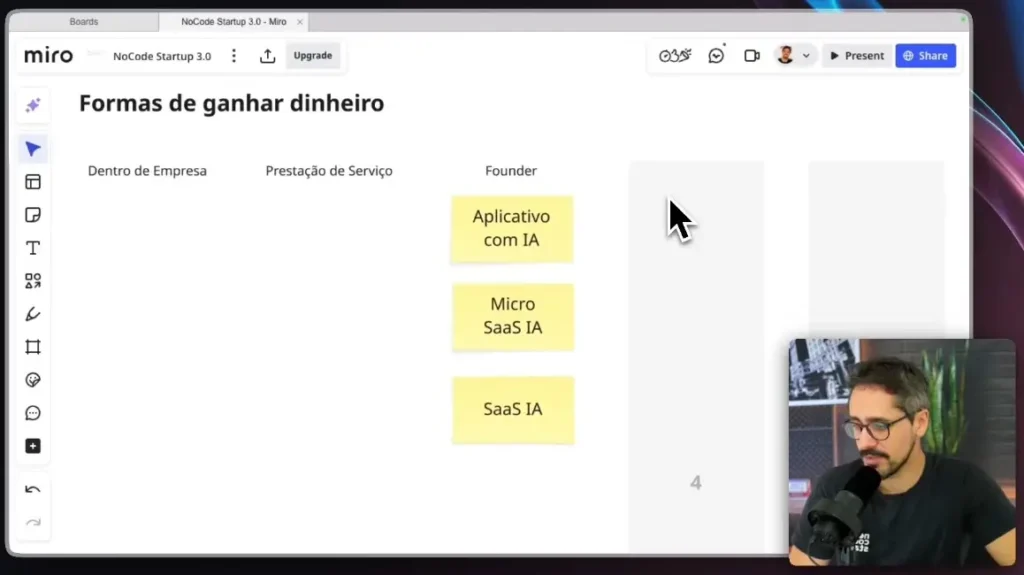
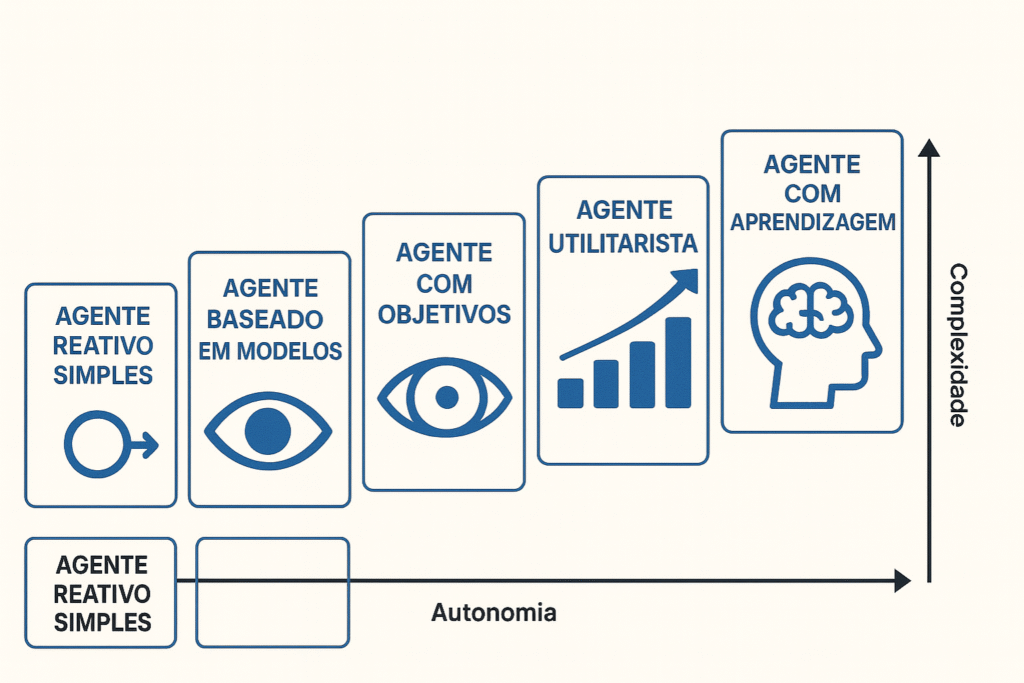
La evolución de la inteligencia artificial ha alcanzado hitos significativos, y la llegada de IA multimodal Esto representa una de las transiciones más importantes en este ecosistema.
En un mundo donde interactuamos simultáneamente con texto, imágenes, audio y vídeo, es lógico que los sistemas de IA también puedan comprender e integrar estas múltiples formas de datos.
Este enfoque revoluciona no solo la forma en que las máquinas procesan la información, sino también cómo interactúan con los humanos y toman decisiones.
¿Qué es la IA multimodal?
IA multimodal Es una rama de la inteligencia artificial diseñada para procesar, integrar e interpretar datos de diferentes modalidades: texto, imagen, audio, vídeo y datos sensoriales.
A diferencia de la IA tradicional, que opera con una única fuente de información, modelos multimodales Combinan varios tipos de datos para un análisis más profundo y contextual.
Este tipo de IA busca replicar la forma en que los humanos comprenden el mundo que les rodea, ya que rara vez tomamos decisiones basándonos en un solo tipo de datos.
Por ejemplo, al ver un vídeo, nuestra interpretación tiene en cuenta tanto los elementos visuales como los auditivos y contextuales.
¿Cómo funciona la IA multimodal en la práctica?
La base de la IA multimodal reside en fusión de datos. Existen diferentes técnicas para integrar múltiples fuentes de información, incluyendo la fusión temprana, la fusión intermedia y la fusión tardía.
Cada uno de estos enfoques tiene aplicaciones específicas dependiendo del contexto de la tarea.
Además, los modelos multimodales utilizan alineación intermodal (o alineación intermodal) para establecer relaciones semánticas entre diferentes tipos de datos.
Esto es esencial para que la IA pueda comprender, por ejemplo, que una imagen de un "perro corriendo" corresponde a un texto que describe esa acción.

Desafíos técnicos de la IA multimodal
La construcción de modelos multimodales implica profundos desafíos en áreas tales como:
- Representación¿Cómo se transforman diferentes tipos de datos —como texto, imagen y audio— en vectores numéricos comparables dentro del mismo espacio multidimensional?
Esta representación es lo que permite a la IA comprender y relacionar significados entre estas modalidades, utilizando técnicas como incrustaciones y codificadores específicos para cada tipo de datos. - Alineación¿Cómo podemos garantizar que las diferentes modalidades estén sincronizadas semánticamente? Esto implica la correspondencia precisa entre, por ejemplo, una imagen y su descripción textual, lo que permite a la IA comprender con exactitud la relación entre los elementos visuales y el lenguaje.
Técnicas como la atención cruzada y el aprendizaje contrastivo se utilizan ampliamente. - razonamiento multimodal¿Cómo puede un modelo inferir conclusiones a partir de múltiples fuentes? Esta capacidad permite a la IA combinar información complementaria (por ejemplo, imagen + sonido) para tomar decisiones más inteligentes y contextualizadas, como describir escenas o responder preguntas visuales.
- Generación¿Cómo generar contenido en diferentes formatos de forma coherente? La generación multimodal se refiere a la creación de contenido como subtítulos para imágenes, respuestas habladas a comandos escritos o vídeos explicativos generados a partir de texto, manteniendo siempre la coherencia semántica.
- Transferir¿Cómo se puede adaptar un modelo entrenado con datos multimodales a tareas específicas? La transferencia de conocimiento permite aplicar un modelo genérico a problemas específicos con una mínima personalización, reduciendo el tiempo de desarrollo y los requisitos de datos.
- Cuantificación¿Cómo podemos medir el rendimiento utilizando criterios comparables en diferentes modalidades? Esto requiere métricas adaptadas a la naturaleza multimodal de los medios, capaces de evaluar la coherencia y la precisión entre texto, imagen, audio o vídeo de una manera unificada y justa.
Principales ventajas de los modelos multimodales
Al integrar múltiples fuentes de información, la IA multimodal ofrece innegables ventajas competitivas.
En primer lugar, aumenta significativamente la precisión en la toma de decisiones, ya que permite una comprensión más completa del contexto.
Otro punto fuerte es la robustez: los modelos entrenados con datos multimodales tienden a ser más resistentes al ruido o a las fallas en una de las fuentes de datos.
Además, la capacidad de realizar tareas más complejas, como generar imágenes a partir de texto (texto a imagen), se basa en este tipo de enfoque.
¿Cómo evaluar modelos multimodales?
Para medir la calidad de los modelos multimodales, se aplican diferentes métricas dependiendo de la tarea:
- BLEU multimodal: evalúa la calidad en tareas de generación de texto con entrada visual.
- Recordatorio@k (R@k): se utiliza en búsquedas multimodales para comprobar si el elemento correcto se encuentra entre los k primeros resultados.
- FID (Distancia de inicio de Fréchet): se utiliza para medir la calidad de las imágenes generadas a partir de descripciones textuales.
Una evaluación precisa es esencial para la validación técnica y la comparación entre diferentes enfoques.
Ejemplos reales de IA multimodal en acción
Varias plataformas tecnológicas ya utilizan IA multimodal a gran escala. El modelo Geminis, El [nombre del modelo] de Google es un ejemplo de un modelo multimodal fundamental diseñado para integrar texto, imágenes, audio y código.
Otro ejemplo es GPT-4o, que acepta comandos de voz e imagen además de texto, ofreciendo una experiencia de interacción de usuario muy natural.
Estos modelos están presentes en aplicaciones como asistentes virtuales, herramientas de diagnóstico médico y análisis de vídeo en tiempo real.
Para obtener más información sobre las aplicaciones prácticas de la IA, consulte nuestro artículo sobre... Agentes de IA verticales: Por qué esto podría cambiarlo todo en el mercado digital.
Herramientas y tecnologías involucradas
El avance de la IA multimodal ha sido impulsado por plataformas como Google Vertex AI, AbiertoAI, Transformers con caras abrazadas, Meta IA y IBM Watson.
Además, existen marcos como PyTorch y TensorFlow Ofrecen soporte para modelos multimodales con bibliotecas especializadas.
Dentro del universo NoCode, existen herramientas como Dificar y constituir Ya están incorporando capacidades multimodales, lo que permite a emprendedores y desarrolladores crear aplicaciones complejas sin necesidad de codificación tradicional.

Estrategias de generación de datos multimodales
La escasez de datos bien emparejados (por ejemplo, texto con imagen o audio) es un obstáculo recurrente. Las técnicas modernas de aumento de datos Las opciones multimodales incluyen:
- Utilizar inteligencia artificial generativa para sintetizar nuevas imágenes o descripciones.
- Autoaprendizaje y pseudoetiquetado para reforzar patrones.
- Transferencia entre dominios utilizando modelos fundacionales multimodales.
Estas estrategias mejoran el rendimiento y reducen los sesgos.
Ética, privacidad y sesgo
Los modelos multimodales, debido a su complejidad, aumentan los riesgos de sesgo algorítmico, vigilancia abusiva y mal uso de los datos. Las mejores prácticas incluyen:
- Auditoría continua con equipos diversos (equipo rojo).
- Adopción de marcos como Ley de IA de la UE y las normas ISO de IA.
- Transparencia en los conjuntos de datos y en los procesos de recopilación de datos.
Estas precauciones evitan impactos negativos a gran escala.
Sostenibilidad y consumo de energía
El entrenamiento de modelos multimodales requiere importantes recursos computacionales. Algunas estrategias para que el proceso sea más sostenible incluyen:
- Cuantización y destilación de modelos para reducir la complejidad.
- Uso de energías renovables y centros de datos optimizados.
- Herramientas como Impacto del CO2 de ML y CodeCarbon para medir la huella de carbono.
Estas prácticas combinan rendimiento con responsabilidad ambiental.
De la idea al producto: cómo implementarlo
Ya sea con Vertex AI, WatsonX o Hugging Face, el proceso de adopción de la IA multimodal implica:
Elección de pila tecnológica: ¿de código abierto o comercial?
La primera decisión estratégica consiste en elegir entre herramientas de código abierto o plataformas comerciales. Las soluciones de código abierto ofrecen flexibilidad y control, lo que las hace ideales para equipos técnicos.
Las soluciones comerciales, como Vertex AI e IBM Watson, aceleran el desarrollo y brindan un sólido soporte a las empresas que buscan productividad inmediata.
Preparación y registro de datos
Este paso es fundamental porque la calidad del modelo depende directamente de la calidad de los datos.
Preparar datos multimodales implica alinear imágenes con texto, audio con transcripciones, vídeos con descripciones, etc. Además, la anotación debe ser precisa para entrenar el modelo con el contexto correcto.
Entrenamiento y perfeccionamiento
Una vez preparados los datos, es hora de entrenar el modelo multimodal. Esta fase puede incluir el uso de modelos fundamentales, como Gemini o GPT-40, que se adaptarán al contexto del proyecto mediante técnicas de ajuste fino.
El objetivo es mejorar el rendimiento en tareas específicas sin tener que entrenar desde cero.
Implementación con monitoreo
Finalmente, una vez validado el modelo, debe ponerse en producción con un sistema de monitoreo robusto.
Herramientas como Vertex AI Pipelines ayudan a mantener la trazabilidad, medir el rendimiento e identificar errores o desviaciones.
El monitoreo continuo garantiza que el modelo siga siendo útil y ético a lo largo del tiempo.
Para equipos que buscan crear prototipos sin código, consulten nuestro contenido sobre... Cómo crear un SaaS con IA y sin código.
Aprendizaje multimodal e incrustaciones

La ética que subyace a la IA multimodal implica conceptos como aprendizaje multimodal autosupervisado, donde los modelos aprenden de grandes volúmenes de datos sin etiquetar, alineando internamente sus representaciones.
Esto da como resultado incrustaciones multimodales, que son vectores numéricos que representan contenido de diferentes fuentes en un espacio compartido.
Estas incrustaciones son cruciales para tareas como indexación intermodal, donde una búsqueda de texto puede devolver imágenes relevantes, o viceversa.
Esto está transformando sectores como el comercio electrónico, la educación, la medicina y el entretenimiento.

Futuro y tendencias de la IA multimodal
El futuro de la IA multimodal apunta al surgimiento de AGI (Inteligencia Artificial General), una IA capaz de operar con conocimiento general en múltiples contextos.
El uso de sensores en dispositivos inteligentes, como los LiDAR en vehículos autónomos, combinado con modelos multimodales fundamentales, está acercando esta realidad.
Además, la tendencia es que estas tecnologías sean más accesibles y se integren en la vida cotidiana, por ejemplo, en la atención al cliente, la atención médica preventiva y la creación de contenido automatizado.
Los emprendedores, desarrolladores y profesionales que dominen estas herramientas estarán un paso por delante en la nueva era de la IA.
Si quieres aprender a aplicar estas tecnologías a tu proyecto o negocio, explora nuestra... Entrenamiento en IA y NoCode para la creación de SaaS..
Aprenda cómo sacar provecho de la IA multimodal ahora mismo.
La IA multimodal no es solo una tendencia teórica: es una revolución en curso que ya está dando forma al futuro de la inteligencia artificial aplicada.
Gracias a su capacidad para integrar texto, imágenes, audio y otros datos en tiempo real, esta tecnología está redefiniendo lo que es posible en términos de automatización, interacción humano-máquina y análisis de datos.
Invertir tiempo en comprender los fundamentos, las herramientas y las aplicaciones de la IA multimodal es una estrategia esencial para cualquiera que quiera seguir siendo relevante en un mercado cada vez más impulsado por los datos y las experiencias digitales enriquecidas.
Para profundizar aún más, consulte el artículo sobre Ingeniería de contexto: Fundamentos, práctica y el futuro de la IA cognitiva Y prepárense para lo que viene.