El avance de los modelos de lenguaje ha transformado nuestra forma de interactuar con la tecnología, y GLM 4.5 Se erige como un hito importante en esta evolución.
Desarrollado por el equipo de Zhipu AI, este modelo ha ido ganando reconocimiento mundial al ofrecer una poderosa combinación de eficiencia computacional, razonamiento estructurado y soporte avanzado para agentes de inteligencia artificial.
Para desarrolladores, empresas y entusiastas de la IA, comprender qué es GLM 4.5 y cómo se compara con otros estándares es crucial. LLMs Es fundamental aprovechar al máximo sus características.

¿Qué es GLM 4.5 y por qué es importante?
O GLM 4.5 Es un modelo de lenguaje de tipo Mezcla de Expertos (MoE), con 355 mil millones de parámetros totales y 32 mil millones de parámetros activos por pasada hacia adelante.
Su arquitectura innovadora permite un uso eficiente de los recursos informáticos sin sacrificar el rendimiento en tareas complejas.
El modelo también está disponible en versiones más ligeras, como la GLM 4.5-Aire, optimizado para lograr una buena relación costo-beneficio.
Diseñado con un enfoque en tareas de razonamiento, generación de código e interacción con agentes autónomos, GLM 4.5 destaca por su soporte para... forma híbrida de pensar, que alterna entre respuestas rápidas y razonamientos profundos a petición.
Características técnicas del GLM 4.5
La ventaja técnica de GLM 4.5 reside en su combinación de optimizaciones de la arquitectura MoE y mejoras en el proceso de entrenamiento. Entre los aspectos más relevantes se encuentran:
Enrutamiento inteligente y equilibrado
El modelo emplea puertas sigmoideas y normalización QK-Norm para optimizar el enrutamiento entre especialistas, garantizando una mejor estabilidad y utilización de cada módulo especializado.
Capacidad de contexto extendido
Con soporte para hasta 128.000 fichas de entrada, GLM 4.5 es ideal para documentos largos, código extenso e historiales de conversaciones profundos. También es capaz de generar hasta 96.000 tokens de salida.
Optimizador Muon y atención de consultas agrupadas
Estos dos avances permiten que GLM 4.5 mantenga un alto rendimiento computacional incluso con la escalabilidad del modelo, lo que beneficia tanto a las implementaciones locales como a las de la nube.
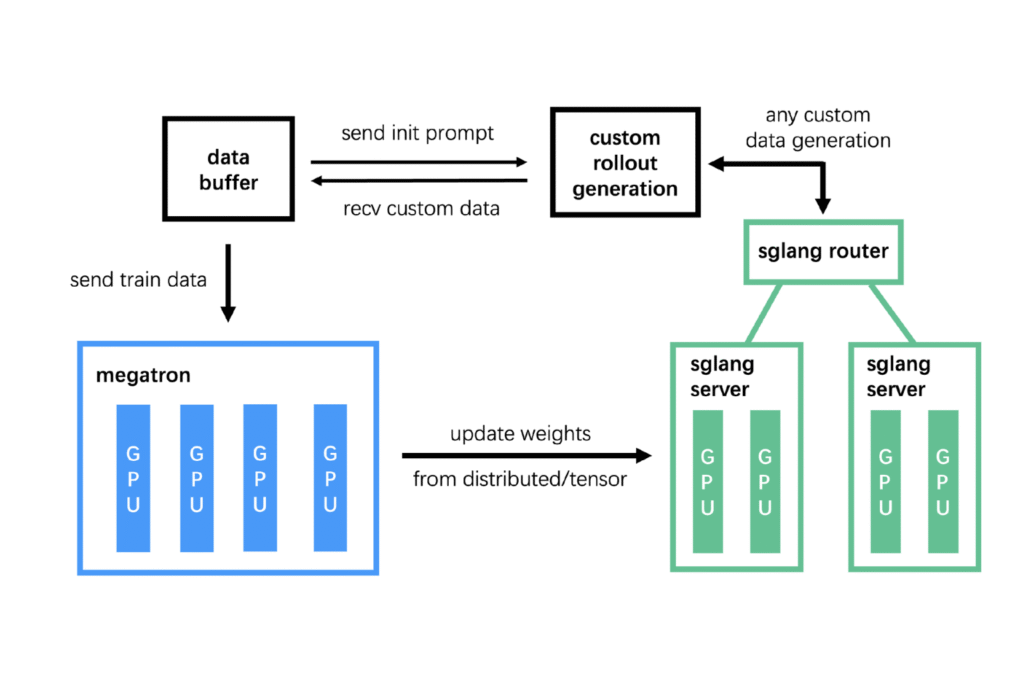
Herramientas, API e integración de GLM 4.5
El ecosistema de IA de Zhipu facilita el acceso a GLM 4.5 mediante API compatibles con el estándar OpenAI, así como SDK en varios lenguajes. El modelo también es compatible con herramientas como:
- vLLM y SGLang para la inferencia local
- ModelScope y HuggingFace Para usar con pesas abiertas
- Entornos compatibles con el SDK de OpenAI para facilitar la migración de tuberías existentes
Para ver ejemplos de integración, visite el Documentación oficial de GLM 4.5.
Aplicaciones en el mundo real: donde GLM 4.5 destaca
GLM 4.5 se diseñó para escenarios donde los modelos genéricos presentan limitaciones. Entre sus aplicaciones se encuentran:
Ingeniería de software
Con un alto rendimiento en pruebas comparativas como SWE-bench verificado (64.2) y Banco terminal (37.5), se posiciona como una excelente opción para automatizar tareas de codificación complejas.
Asistentes y agentes independientes
En las pruebas Banco TAU y BrowseComp, GLM 4.5 superó a modelos como Claude 4 y Qwen, demostrando ser eficaz en entornos donde la interacción con herramientas externas es esencial.
Análisis y elaboración de informes de datos complejos.
Gracias a sus sólidas capacidades contextuales, el modelo puede sintetizar informes extensos, generar ideas y analizar documentos largos de manera eficiente.
Comparación con GPT-4, Claude 3 y Mistral: rendimiento frente a coste
Uno de los aspectos más destacables del GLM 4.5 es su coste significativamente inferior al de modelos como... GPT-4, Claude 3 Opus y Mistral Grande, aunque ofrece un rendimiento comparable en diversas pruebas de referencia.
Por ejemplo, si bien el costo promedio de generar tokens con GPT-4 puede superar US$ 30 por millón de tokens generados, El modelo GLM 4.5 funciona con promedios de US$ 2,2 por millón de producción, con opciones aún más asequibles como GLM 4.5-Aire por apenas US$ 1.1.
En términos de rendimiento:
- Claude 3 Sobresale en tareas de razonamiento lingüístico, pero GLM 4.5 se le acerca en razonamiento matemático y ejecución de código.
- Mistral Sobresale en velocidad y compilación local, pero no alcanza la profundidad contextual de 128k tokens como GLM 4.5.
- GPT-4, Aunque robusto, exige un alto precio por un rendimiento que, en muchos escenarios, GLM 4.5 iguala a una fracción del coste.
Esta relación costo-beneficio posiciona al GLM 4.5 como una excelente opción para startups, universidades y equipos de datos que buscan escalar aplicaciones de IA con un presupuesto limitado.
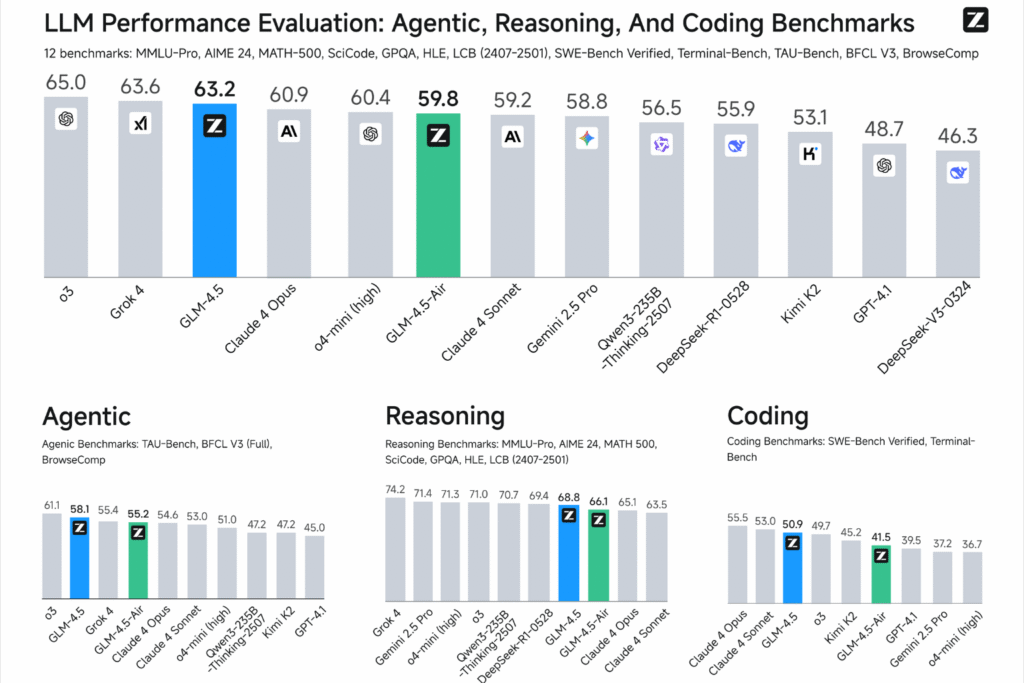
Comparación del rendimiento con otros LLM
GLM 4.5 no solo compite con las grandes marcas del mercado, sino que también las supera en varios aspectos. En cuanto al razonamiento y la ejecución de tareas estructuradas, obtuvo los siguientes resultados:
- MMLU-Pro: 84.6
- AIME24: 91.0
- GPQA: 79.1
- LiveCodeBench: 72.9
Fuente: Informe oficial de Zhipu AI
Estas cifras son claros indicadores de un modelo maduro, listo para su uso comercial y académico a gran escala.

Futuro y tendencias de GLM 4.5
La hoja de ruta de Zhipu AI apunta a una expansión aún mayor de la línea de productos. GLM, con versiones multimodales como la GLM 4.5-V, lo que añade información visual (imágenes y vídeos) a la ecuación.
Esta dirección sigue la tendencia de integrar texto e imágenes, lo cual es esencial para aplicaciones como el reconocimiento óptico de caracteres (OCR), la lectura de capturas de pantalla y los asistentes visuales.
También se esperan versiones ultraeficientes, como por ejemplo la GLM 4.5-AirX y opciones gratuitas como GLM 4.5-Flash, que democratizan el acceso a la tecnología.
Para estar al día de estas actualizaciones, se recomienda supervisar el sitio web oficial del proyecto.
Un modelo para quienes buscan eficiencia con inteligencia.
Al combinar una arquitectura sofisticada, integraciones versátiles y un excelente rendimiento práctico, el GLM 4.5 Se destaca como una de las opciones más sólidas en el mercado de LLM.
Su enfoque en el razonamiento, los agentes y la eficiencia operativa lo hace ideal para aplicaciones de misión crítica y escenarios empresariales exigentes.
Explora más contenido relacionado en Curso de formación de agentes con OpenAI, Aprende sobre la integración en Hacer curso (Integromat) y consulta otras opciones para Programas de formación en IA y NoCode.
Para aquellos que buscan explorar lo último en modelos de lenguaje, GLM 4.5 es más que una alternativa: es un paso adelante.