¿Sabías que integrar WhatsApp con N8N usando una API no oficial de WhatsApp puede transformar la automatización de tu negocio?
Las API no oficiales de WhatsApp son una alternativa interesante para quienes buscan mayor flexibilidad y ahorro, sin comprometer la legalidad.
Aunque Meta no vincula directamente estas API, sí permiten crear automatizaciones robustas, enviar mensajes, configurar chatbots e integrar sistemas con WhatsApp de forma práctica y eficiente. En este artículo aprenderás a:
- Crea tu cuenta en la API no oficial;
- Configurar el integración con N8N;
- Enviar mensajes automáticamente por WhatsApp;
- Active automatizaciones inteligentes con chatbots e IA;
- Utilice webhooks para recibir y procesar mensajes.
¡Todo esto utilizando herramientas accesibles, como ZAPI y N8N, para transformar tu comunicación en WhatsApp en un proceso automatizado y eficiente! ¡Feliz lectura!
API no oficial de WhatsApp: ¿Qué son?

Las API no oficiales de WhatsApp son desarrolladas por empresas que no tienen un vínculo directo con Meta (la empresa responsable de WhatsApp). Esto no quiere decir que sean ilegales, sino que terceros ofrecen soluciones para integrar WhatsApp con sistemas automatizados.
Si bien la API oficial está vinculada directamente a Meta y tiene reglas de uso estrictas, las API no oficiales ofrecen más flexibilidad y rentabilidad. Varias empresas los utilizan ampliamente para crear automatizaciones, chatbots y enviar mensajes masivos.
Si quieres saber más sobre las diferencias entre los API no oficial de WhatsApp y API oficial de WhatsApp Business, consulte el artículo completo en el blog de NoCode Startup.
Entre las opciones más populares de la API no oficial de WhatsApp se encuentran:
- API Z: herramienta ampliamente utilizada por su sencillez y funcionalidades avanzadas;
- MegaAPI: conocido por su estabilidad y soporte técnico;
- API de evolución: Destaca por su fácil integración con otros sistemas.
¿Por qué utilizar API no oficiales en N8N?
El uso de una API no oficial de WhatsApp en N8N le permite crear integraciones robustas y personalizadas, garantizando flexibilidad y ahorro en la comunicación con los clientes. Al usar las API no oficiales de WhatsApp en N8N, obtienes:
- Flexibilidad: personalizar el envío de mensajes, crear flujos automatizados e integrarlos con otros sistemas;
- Economía: Utilice alternativas asequibles sin comprometer la funcionalidad
- Velocidad de implementación: Las API no oficiales son fáciles de configurar y tienen documentación detallada;
- Automatización completa: Envía mensajes, respuestas automáticas y crea chatbots de forma práctica.
En otras palabras, con la API no oficial de WhatsApp, puedes configurar flujos automatizados, enviar mensajes automáticamente e incluso crear chatbots inteligentes.
Además, puede integrar estas funciones con otras herramientas para ampliar aún más sus capacidades.
A continuación, comprenderás cómo configurar tu cuenta Z-API y comenzar a integrarte con N8N para optimizar el envío de mensajes a través de WhatsApp.
¿Cómo funciona la integración con la API no oficial de WhatsApp? Mira el paso a paso
Integrar WhatsApp con N8N Usar una API no oficial de WhatsApp es un proceso simple y directo. La principal ventaja de este método es la flexibilidad, ya que permite crear automatizaciones personalizadas para enviar y recibir mensajes.
Esto además de permitir la creación de chatbots y agentes de inteligencia artificial (IA). ¿Vamos a entender cómo funciona?
Para realizar la integración utilizaremos la Z-API, una de las API no oficiales más populares. ZAPI te permite enviar mensajes y configurarlos automáticamente a través de WhatsApp. Vea los pasos esenciales para configurar:
Paso 1 – Registro en la API Z-API:
El primer paso es registrarse en la plataforma. Para ello, siga los pasos a continuación:
- Vaya al sitio web oficial de Z-API y haga clic en la opción “Realizar una prueba gratuita”. Si aún no tiene una cuenta, haga clic en el enlace proporcionado para iniciar el proceso de registro;
- Llene los campos requeridos con sus datos y al terminar será dirigido al panel de control de Z-API;
- En el panel de Z-API, verá un panel que muestra sus instancias. Cada instancia corresponde a un número de WhatsApp vinculado. Para conectar su número al panel de control de Z-API, haga clic en la instancia que desea utilizar;
- En la pantalla de instancia, encontrará un código QR. Para conectar tu número, abre WhatsApp en tu dispositivo, ve a configuración, haz clic en “Dispositivos conectados” y luego en “Agregar un dispositivo”.
- Apunta la cámara al código QR que se muestra en la Z-API, de la misma manera que lo haces para usar WhatsApp Web;
- Una vez que el número se haya vinculado correctamente, el panel de Z-API indicará que la instancia está "Conectada".
Ahora estás listo para comenzar. integrar WhatsApp con N8N y utilizar las funciones de la API no oficial.
Paso 2: Configuración de la API en N8N
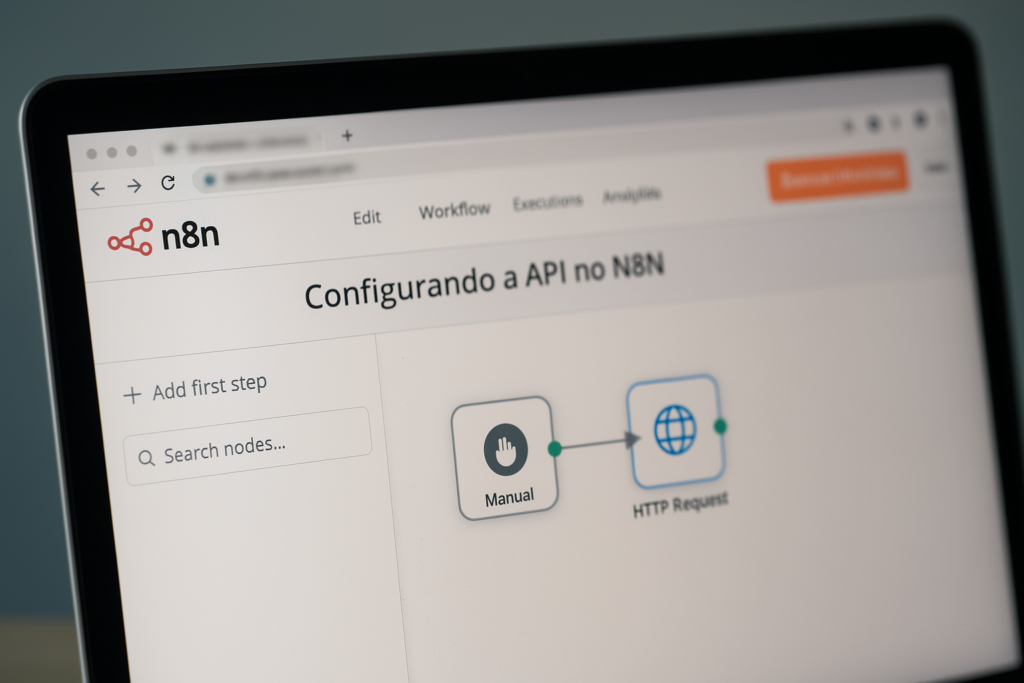
Así que el siguiente paso es configurar API en N8N para que la integración de WhatsApp funcione correctamente. Para ello, siga los pasos a continuación:
- Accede a tu cuenta N8N y haz clic en la opción para crear un nuevo flujo de trabajo;
- Agregue un disparador manual haciendo clic en el botón Agregar y seleccionando “disparador manual” de la lista de opciones;
Dentro del flujo de trabajo, agregue un nodo de tipo “Solicitud HTTP” para realizar la llamada a la API de WhatsApp; - Establezca el método en “POST” e ingrese la URL proporcionada por Z-API, que contiene el punto final para enviar mensajes (por ejemplo, “api.z-api.io/instances/{tu-instancia}/sendText“);
- En el campo “Encabezados”, agregue la información de autenticación, incluido el token del cliente y el token de seguridad de la cuenta, como se indica en la documentación de Z-API;
- En el campo “Cuerpo” ingrese los parámetros obligatorios, como el número del destinatario y el mensaje a enviar.
- Después de configurar los campos necesarios, haga clic en “Ejecutar” para probar el envío del mensaje. N8N mostrará una confirmación de éxito.
Una vez que envíe exitosamente el mensaje, la interfaz N8N mostrará la respuesta, confirmando que la integración está funcionando correctamente.
Paso 3 – Prueba de envío de mensajes:
Bien, ahora que has configurado la API en N8N, es momento de probar el envío del mensaje para asegurarte de que la integración funciona correctamente. Siga los pasos a continuación:
- En N8N, haga clic en la opción “Ejecutar” para ejecutar el flujo de trabajo que acaba de configurar;
- Verifique la interfaz N8N para ver si aparece el mensaje “Nodo ejecutado exitosamente”. Esto indica que el flujo se ejecutó correctamente;
Ahora, abre WhatsApp en el dispositivo que vinculaste a la Z-API y verifica si el mensaje enviado a través del flujo de trabajo llegó al destinatario; - Por lo tanto, si el mensaje no se envió, revise la configuración de la API en N8N, especialmente los campos URL, Encabezados y Cuerpo;
- Si el mensaje llegó correctamente ¡felicitaciones! La integración entre WhatsApp y N8N utilizando la API no oficial fue exitosa.
Paso 4 – Automatizar la recepción de mensajes:
Hasta ahora tu integración está funcionando correctamente, el siguiente paso es automatizar la recepción de mensajes en N8N:
- En N8N, abra el flujo de trabajo que creó anteriormente o, si lo prefiere, cree un nuevo flujo de trabajo.
- Añade un nodo disparador de tipo “Webhook” para recibir mensajes automáticamente;
- Establezca el método webhook en “POST” y elija un nombre para la ruta, como “webhook-api-whatsapp”;
- Copie la dirección del webhook que se generará automáticamente;
- En el panel de Z-API, acceda a la instancia vinculada y vaya a la configuración del Webhook;
- Pegue la dirección del webhook copiada en el campo indicado para recibir mensajes;
- Guarde los cambios y regrese a N8N para verificar que el webhook esté activo y listo para recibir mensajes.
Luego, cada vez que se reciba un nuevo mensaje en el WhatsApp vinculado, N8N lo capturará automáticamente. Además, puede configurar acciones adicionales, como respuestas automáticas o procesamiento de los datos recibidos.
Conclusión

Integrar WhatsApp con N8N utilizando una API no oficial de WhatsApp como Z-API es una solución práctica y eficiente para automatizar procesos y mejorar la comunicación con tus clientes.
Siguiendo las instrucciones paso a paso de este artículo, estará listo para transformar la gestión de la comunicación de su empresa con recursos avanzados y accesibles.
Entonces, ¿qué tal empezar ahora y convertirte en un experto en automatización con N8N? Aprovecha ahora y accede gratis Curso NoCode Startup N8N. ¡Un curso gratuito 100% que te enseñará a crear integraciones increíbles y automatizar procesos de manera eficiente!
No pierdas esta oportunidad de aprender de expertos y mejorar tus habilidades de automatización.